Gartner Data & Analytics London May 2026: My Honest No-BS Takeaways
Main topics: foundations, context, vendor strategy, governance is also king and queen, methodologies and awesome data community

Last week I was at Gartner Data & Analytics London, where I presented and demoed the latest ServiceNow innovations in data & analytics, together with a great conversation with Mircea Danciulescu WPP Global Data Manager.

This is my trip report with my personal, honest, No-BS takeaways of the conference
(For comparison, check out the Gartner D&A Orlando March 2026 takeaways)
1. The basics and foundations
Of course context is the current hot topic. But here’s the thing...most people are still at the absolute basics. For example, Andres Garcia-Rodeja gave a 30 min talk on how to build a context layer, on the last day, last hour, to a packed room. After the talk, he had a line of folks asking him questions for 30 mins. And it was all basic foundational questions.
Now let’s look at the data, because the numbers tell a pretty uncomfortable story.
Only 1 in 5 AI initiatives are achieving ROI in 2025. Let that sink in. 4 out of 5 AI projects are not delivering.

Meanwhile, 6 out of 10 European IT leaders have real concerns about cost overruns from AI agents, but only 1 out of 10 D&A and AI leaders share that concern. So either D&A leaders are more confident they can manage it or they’re not paying attention to the right signals.

And 47% of European organizations have already put financial guardrails or AI FinOps practices in place, which tells you the governance infrastructure is being built whether or not leadership is worried about it.

The readiness picture is even more sobering. Data availability and quality is still the number one barrier to AI implementation. Only 26% of D&A or AI leaders think their data engineering practices are highly effective for existing AI use cases. Only 13% say their D&A governance function can fully lead AI governance. And 90% of D&A leaders say their architecture needs a minor or significant overhaul to support new use cases (of course… the problem is tech, right!?!?)

But here’s the twist: CEOs are betting fairly equally among CISO, CIO and CDOs to lead AI. The Gartner CEO survey shows that CDOs rank third in perceived AI savviness across the C-suite. There’s a massive gap between what CEOs expect from data leaders and where data leaders actually are. This is a very strong indicator that CIO and CDOs need to align on the strategy! So for the CDOs not working closely with your CIO… you are in a disadvantage.
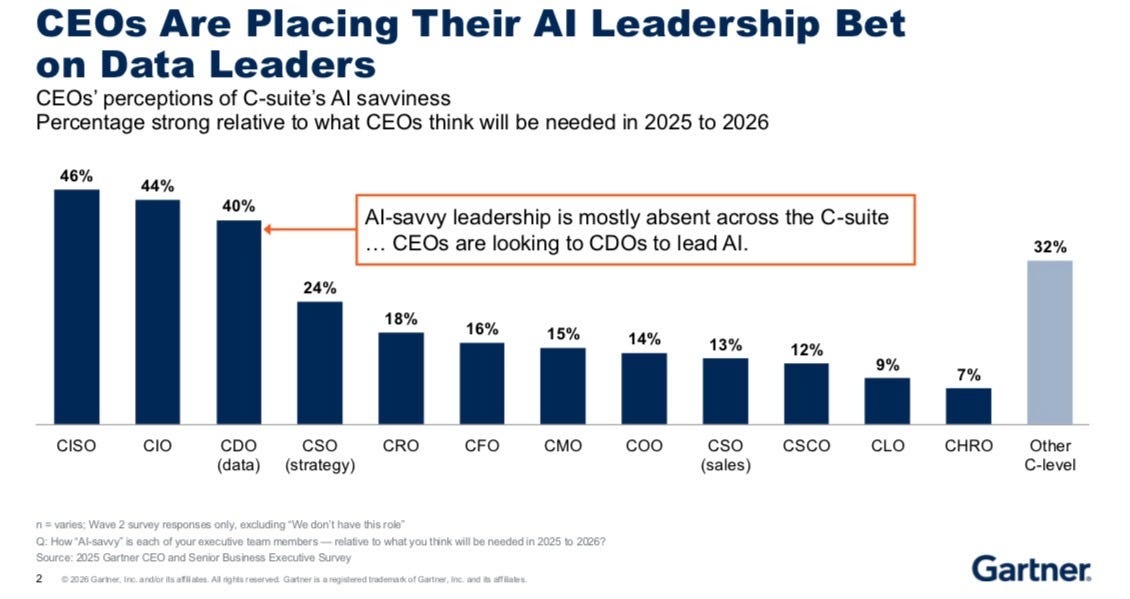
So what’s the answer? Gartner keeps saying “this is the year of the foundation.” And I have to say: when has it NOT been the year of the foundation? It’s always the year of the foundation. That’s kind of a running joke at this point.
In addition to the WHAT you should be doing (stating the obvious):


There was also conversations about HOW to build foundations, and lessons learned:




The “flip the traditional approach” message (i.e start with business outcomes and work backwards) keeps needing to be said because organizations keep doing it backwards.
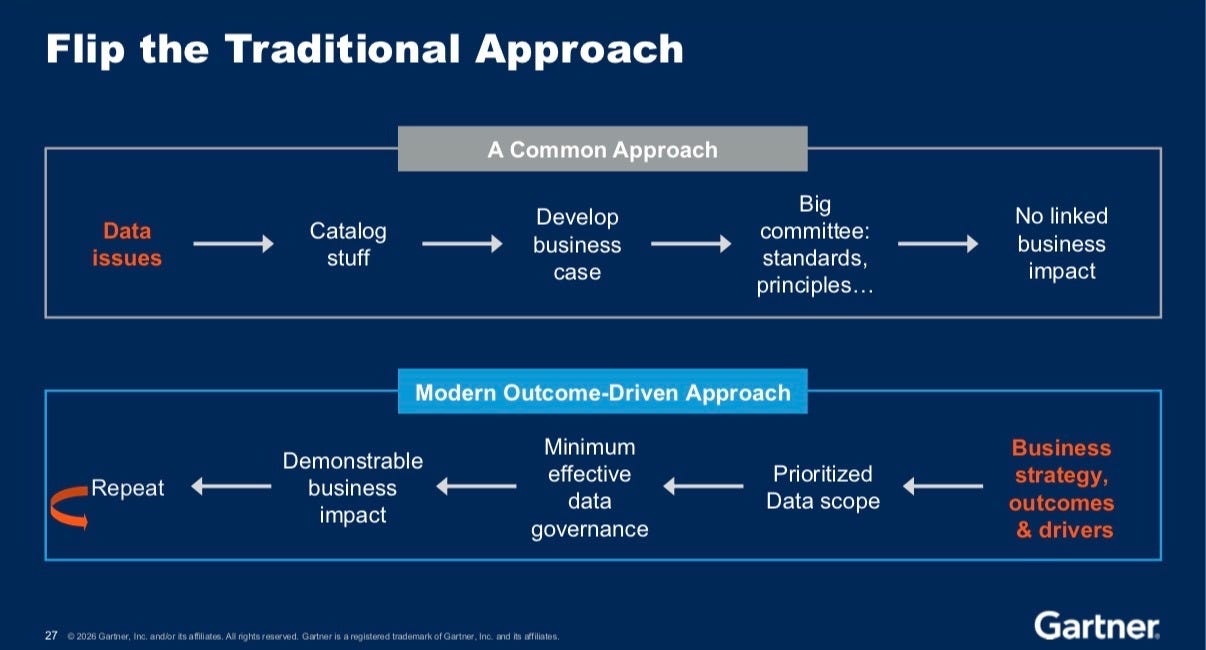
Finally, Gartner presented three archetypes of AI ambition: AI-Cautious, AI-Opportunistic, and AI-First. I want to push back on the AI-Cautious framing. I don’t think anybody should be positioning themselves as AI-Cautious. If Gartner is validating caution as a legitimate archetype, that’s something worth challenging. Being cautious isn’t a strategy. It’s a posture that leaves you behind.
2. Context, Context, Context.
Context is king and queen. Everyone is talking about context layers and context platforms. Vendors are rebranding as context platforms, context layers, context engines. Context, context, context.

“Semantics, knowledge graphs and ontologies are no longer niche technologies for specialized domains but essential components of AI-ready data infrastructure” - Gartner 2026

So build knowledge graphs... now!
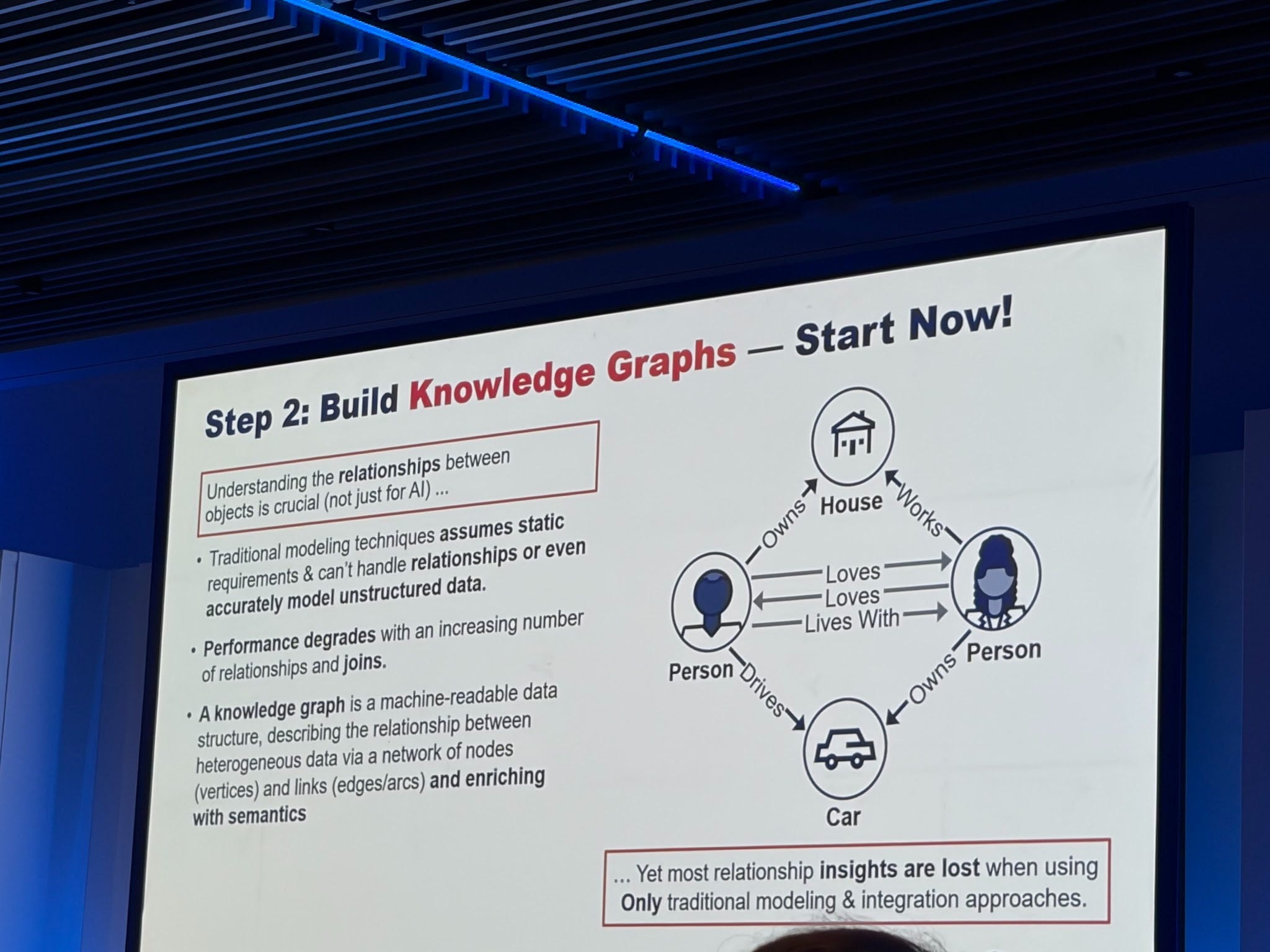
But, what is context? This sums it up pretty nicely:
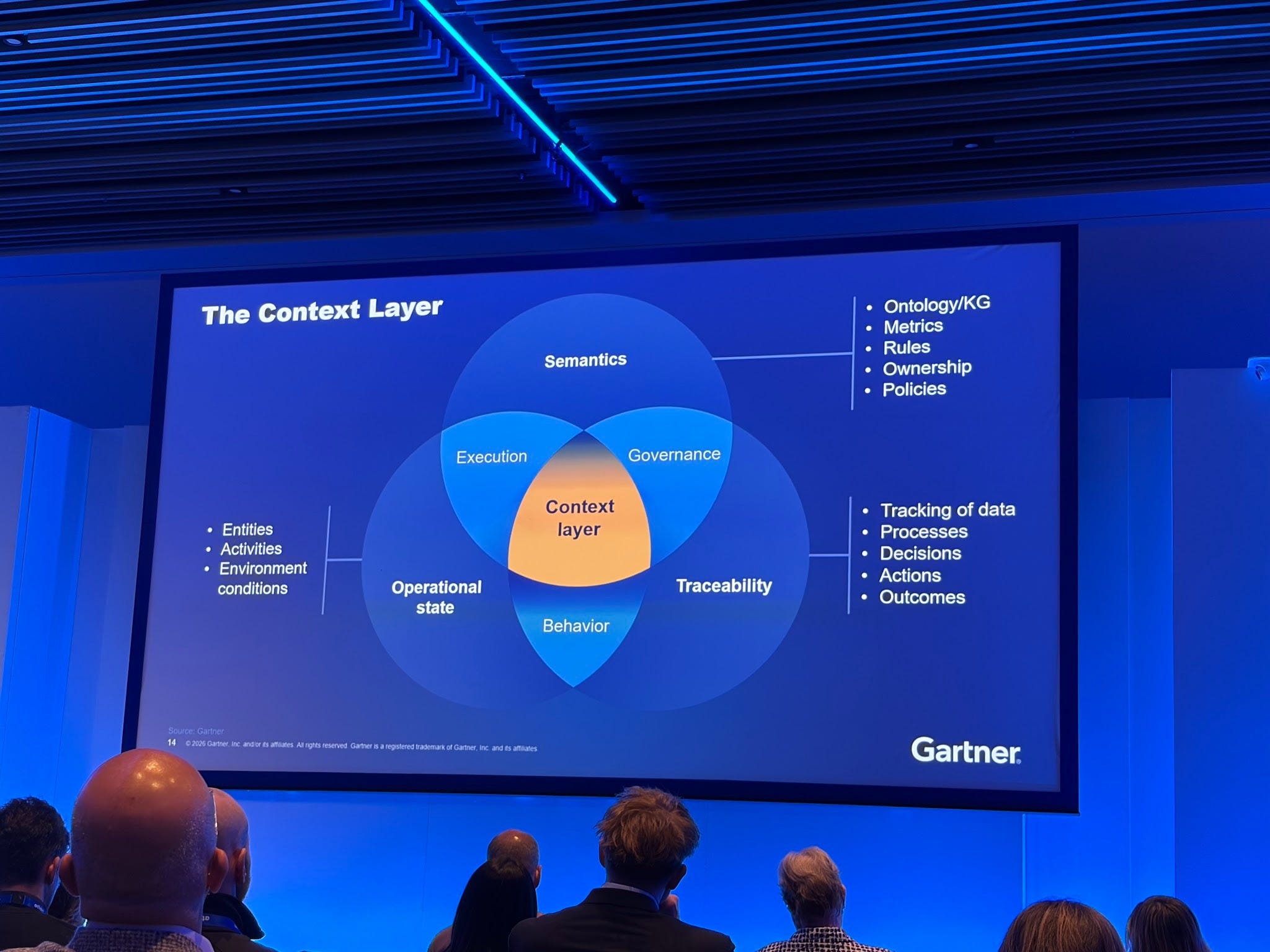
Context consists of semantics: your ontologies, your business glossaries, your metrics definitions. It’s also rules, policies, and ownership. And also knowledge graphs. That’s the natural starting point, and it’s why data catalogs and metadata management tools are rebranding as context platforms.
Context also includes your operational state: your entities, your activities, your environmental conditions. What is actually happening in your business right now (i.e. operations) not just after the fact (i.e. analytics)?
And context includes provenance: the tracking of data, the processes it went through, the decisions that were made, the actions that were taken, the outcomes that resulted. Who decided what, when, and why? The decision traces.
I would actually extend this to include more: Users, Access, Assets. You want to know the context about users (who they are, in what department they are in, or what type of customer cohort they are in), what access they have, etc.
So if you are looking at context layer offerings, you need to be asking how much of the context is actually being supported. Data catalogs rebranded as context layer platforms are not for the AI-first archetypes.

Also, remember that when you need high reliability and trust, you stick with deterministic approaches and leverage the power of semantics. Not probabilistic inference. Deterministic, semantics-powered reasoning.

One thing I’m really excited about is to see how the practices of knowledge engineering are coming up more and more. The faster organizations move toward knowledge engineering as a practice, the faster they get value from agentic AI.

How are folks starting their knowledge engineering work? Per a live poll, 60% are starting with semantic layers for BI. The other 40% are going straight to ontologies and knowledge graphs. Honestly, if you are coming from a traditional data & analytics practice (building star schemas for BI dashboards), you should be starting with semantic layers for BI, before jumping to ontologies. If you are coming from an operational background where you are integrating data to support operational use cases that require data from different silos (i.e. Customer 360), then you may want to jump straight to ontologies and knowledge graphs

A clear message: you can’t buy context. Context already exists in your organization. It lives in your systems, your processes, your people’s heads, your institutional and tacit knowledge. It’s not missing. It’s fragmented and poorly managed.
Also remember: context is a means to get work done. It’s just one piece of the puzzle. Investing in content layer specific point solutions have a risk because the data management market is converging: “Point solutions are becoming obsolete and turning into features of data management platforms”

Which takes me to the next point.
3. What is your vendor strategy?
One of the best sessions at the conference was a panel on evaluating your strategic data management platform choices. Gartner brought together Ehtisham Zaidi, Robert Thanaraj, and Roxane Edjlali, moderated by Daniel Cota. Kudos to Gartner for running a truly honest, No-BS panel. You could tell it wasn’t scripted, and the analysts were willing to critique their own categories. You need to do more of these!

There are three main ways to build a converged data management platform (CDMP).
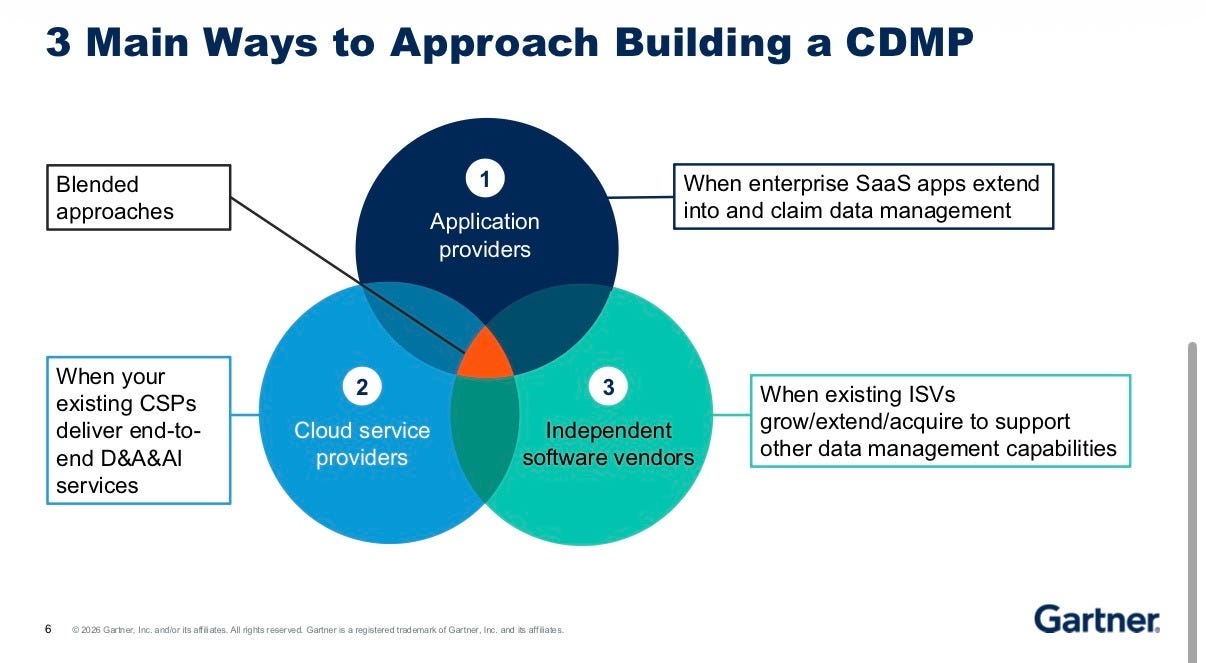

Option 1 — Cloud Service Providers (CSP-centric): Best when you’re already on one cloud, you want pre-integrated capabilities, and time to market matters more than differentiation. Ehtisham acknowledge that not all data management capabilities are created equal in any of these cloud data management ecosystems. Especially integration, metadata, quality, and governance.” Hyperscalers’ metadata tools typically only scan inside their own ecosystem. Multi-cloud buyers will still need ISVs.
Option 2 — Independent Software Vendors (ISV-centric): Best for best-of-breed depth, cloud neutrality, and high-maturity for specific capabilities. But Robert flagged the risks: you risk recreating the fragmented best-of-breed stitching problem of the past. And acquisition risk is real: if your ISV gets acquired by a hyperscaler or app vendor that isn’t your strategic partner, what happens to your investment?
Option 3 — Application providers (App-centric): Best when your data and use case requirements are fulfilled within the application’s footprint. Roxane called out that the next frontier is not going to be who owns your data, but who owns your metadata. Furthermore, application vendors know the semantics/context, of their own applications better than anyone else. While hyperscalers and ISVs are trying to infer the semantics, application vendors already hold it. The issue is that organizations use multiple applications.
What I found when talking to data leaders is that most don’t have a clear vendor and partner strategy. The best answer I heard was from a leader who had developed a tiered approach almost like a medallion architecture for vendors.
Think about it in three tiers across two dimensions: Strategic and Critical. These could be independent.
A vendor can be Strategic: aligned with your future direction, part of your long-term platform bet, where you’re expanding your footprint and getting preferred terms.
A vendor can be Critical: your business operations run on it today, it’s deeply embedded, it’s not going away anytime soon.
And the key insight is that a vendor can be critical without being strategic because you may not be doubling down. A vendor can be strategic without being critical because you may be open to switching, especially in this fast-paced AI world.
You should ask yourself: where is the gravity of data and context? Where should governance live? Where do the use cases live? Where are actions taking place? Where does the work get done? The ultimate question is: who is going to enables us to get the work done best?
4. Governance is also King and Queen
The scope of governance is already big and it’s increasing.
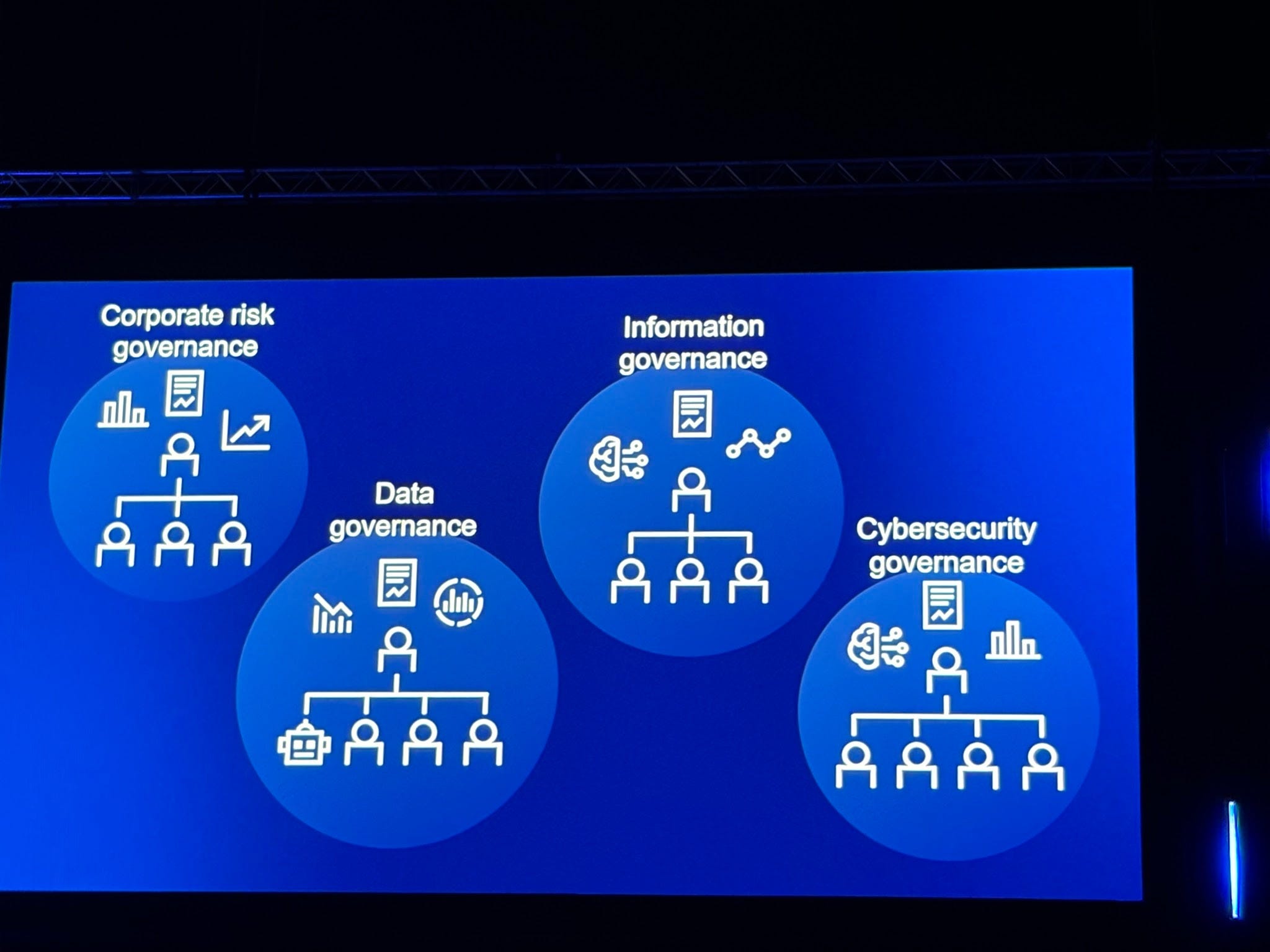
I really enjoyed Anurag Raj‘s deep dive on the future of D&A governance. We have this tendency in the data world to think of governance as just “data governance”: catalogs, glossaries, quality rules, lineage. But Anurag showed the full picture: data governance, AI governance, analytics governance, cybersecurity, MDM, decision governance, corporate risk governance, IT governance. This is converging. AI is forcing what he called a “governance singularity.” These boundaries are blurring whether we like it or not.
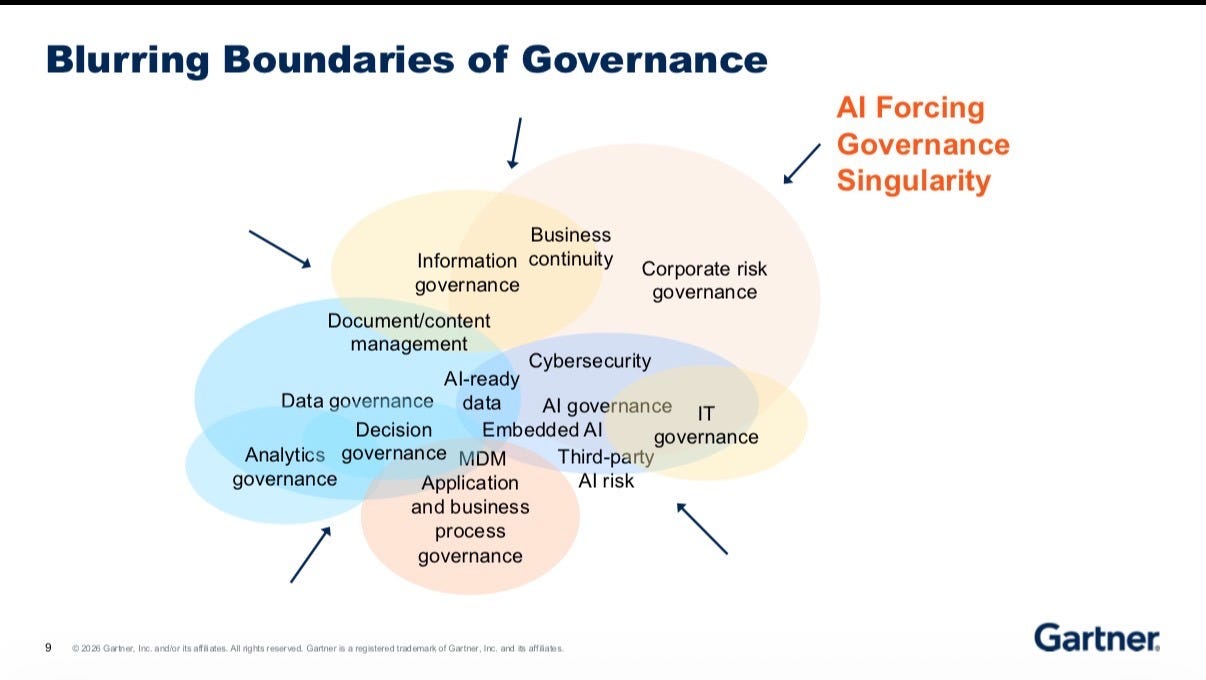
And there is so much to govern. We need to be clear on why it needs to be governed. This is a good framework to think about it:

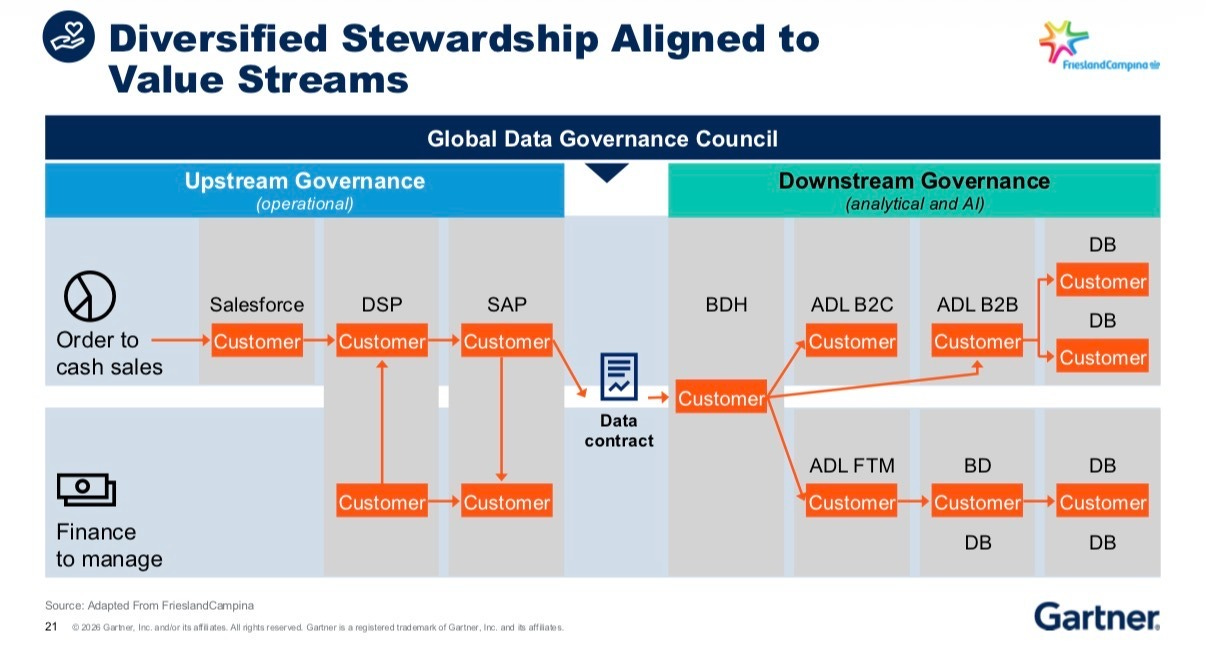
And here’s the thing that has clicked for me since I joined ServiceNow: governance is already happening on the operational side. People in operations are doing governance every day: they’re managing data entry rules, they’re responsible for source data correctness, they’re notifying teams of structural changes. They may not be calling it governance, but they’re doing it.
The data and analytics world has been so focused on its own slice that it has largely ignored the operational governance that’s already happening upstream. And that’s a problem because the outcomes we care about depend on what’s happening operationally.
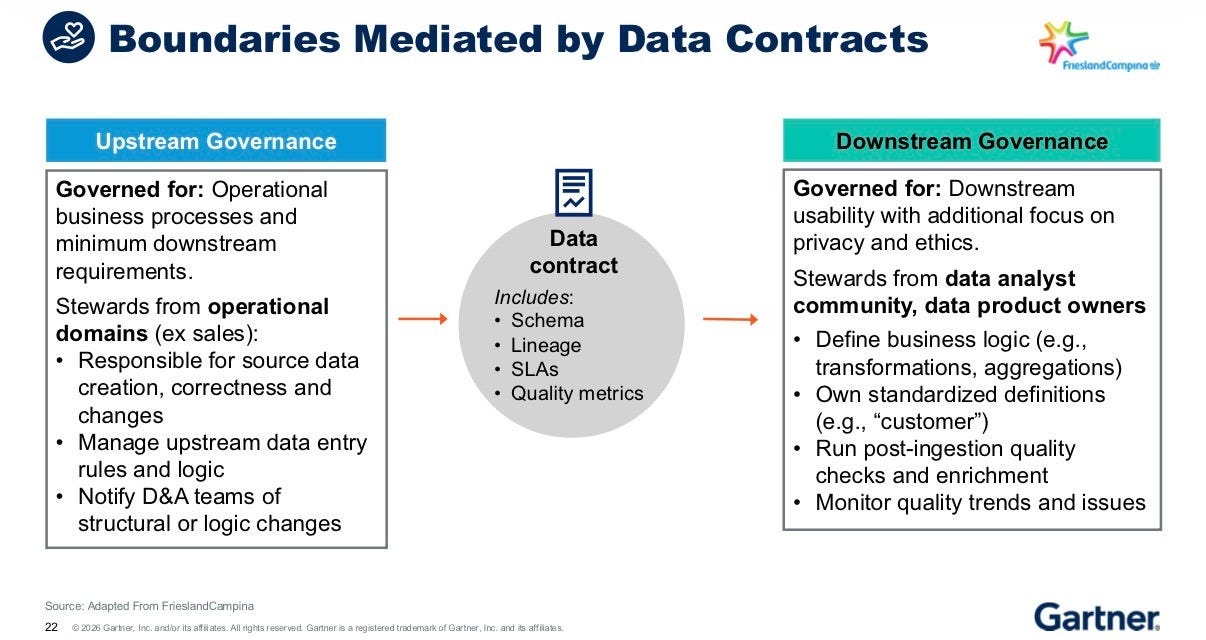
The following is a great visual where data contract serve as the bridge between upstream operational governance and downstream analytical governance. It carries schema, lineage, SLAs, and quality metrics. It’s the formal handshake between the people who create the data and the people who use it. This is more than data contracts for data products, because those are contracts for the data and analytics world.
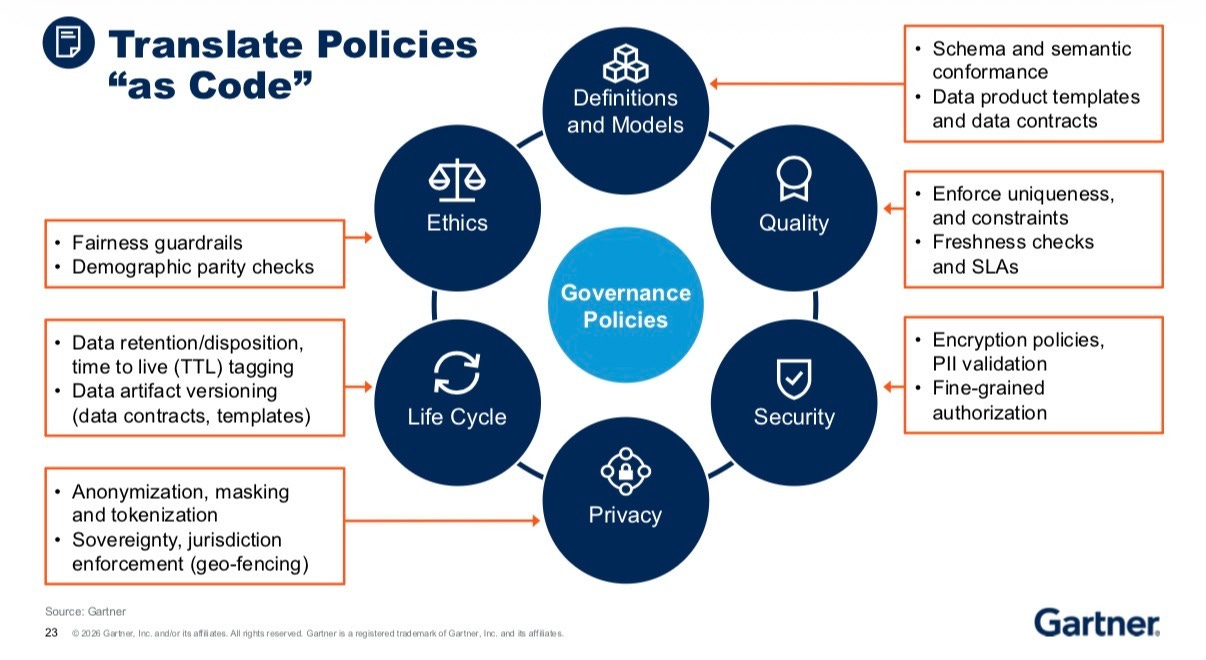
This connects to policy as code, the idea that governance policies get translated into enforceable code, not just documentation. Anurag laid out six types of policies: definitions and models, quality, security, privacy, ethics, lifecycle. This is a great starting point to think about the breath of how much policy could be translated to code.
The open question for me: who and what is the enforcement engine? Implementation is tractable. Enforcement at scale is still unsolved IMO.
5. Methodologies: what we are not talking about and we need to!
What’s STILL missing though, and this is my main critique of the data & analytics industry, is a clear methodology for how you move through maturity by use case, not by big sequential layers. Organizations hear “build the foundation first” and they sometimes get into waterfall mode and boil the ocean. Big foundation project. Then the next layer. Then the next. Meanwhile, nothing is delivered and everyone loses patience. We need to present use cases directly from IT, HR, Customer, Finance, Sales, Risk & Security, etc and how you get from foundations with context and governance to AI wins.
What I’ve always advocated for is what I call the iron-thread approach. You start from the outcome, the work you’re actually trying to do. You identify the minimum foundation to support that outcome. You execute end-to-end, show value, achieve the outcome, AND build the foundation simultaneously. Then you repeat. You’re not doing foundations first and value later. You’re doing them together, use case by use case, constantly showing progress. That’s the pay-as-you-go methodology.
We should consider doing the “day in the life of a piece of data.” Follow a specific piece of data through its complete journey. Where does it originate in your operations? How does it flow through your systems? Who touches it, when, why? What governance checkpoints does it hit? Where does it land in your analytics or AI systems? What insights get generated? And how do those insights feed BACK into your operations?
When you do that exercise, something interesting happens. You stop arguing about abstract governance frameworks and you start discovering exactly what you actually need, what context matters, what policies apply, what contracts should exist between teams, what the real stewardship responsibilities are. It makes the abstract concrete.
During customer meetings, I had the opportunity to bring people from the operational side and people from the data analytics side to sit at the same table for the first time. Looking at each other. Realizing they needed to work together. That doesn’t happen enough. The “day in the life” exercise is a way to force that conversation because you can’t follow the journey of a piece of data without bringing both sides of the house into the room.
At the end of the day, when you pull all of this together — data, semantics, context layers, governance, data contracts, policy as code, knowledge graphs, insights, analytics — you realize we’re not talking about data management. We’re talking about how work gets done in an enterprise. That’s the real conversation. And the sooner we frame it that way, the sooner we start making real progress.
6. Awesome Community
I started engaging with Gartner analyst about a decade ago. My previous startup, Capsenta was a Gartner Cool Vendor in Data Integration in 2016! That is when I first Mark Beyer and Ehtisham Zaidi. I believe this was my 10th Gartner D&A conference (I’ve been attending both Orlando and London for the past 5 years). It’s been fantastic to get to know more and more analyst over the years.


Also, a great thing about Gartner is that you get to connect with more friends and colleagues from the data community.





If you attended Gartner D&A London, what were your takeaways? I’d love to hear what resonated or what you’re pushing back on.
Thank you, Juan, for attending the conference & sharing an informative summary with insightful perspectives.