Gartner Data & Analytics March 2026: My Honest No-BS Takeaways

Gartner D&A is always a mix of signal and noise. These are my personal observations from Gartner D&A 2026 where I’m trying to identify the single from the noise
The Dirty Secret Nobody Wants to Admit
Everyone is behind. Not a little behind. Significantly behind. And yet if you walked the conference floor or listened to the hallway conversations, you would think every organization was crushing it with AI. They are not. They are shipping things just to say they shipped something. Board pressure is real: over half of IT and AI leaders feel pushed into adopting GenAI tools before they are ready. The result is a lot of activity that looks like progress but is not.

This is not a technology problem. This is a leadership and prioritization problem.
And by the way, this is the year of foundations. Of course it is. It always is. Until we actually build them.
The Three Numbers That Tell the Whole Story
From the Gartner opening keynote:
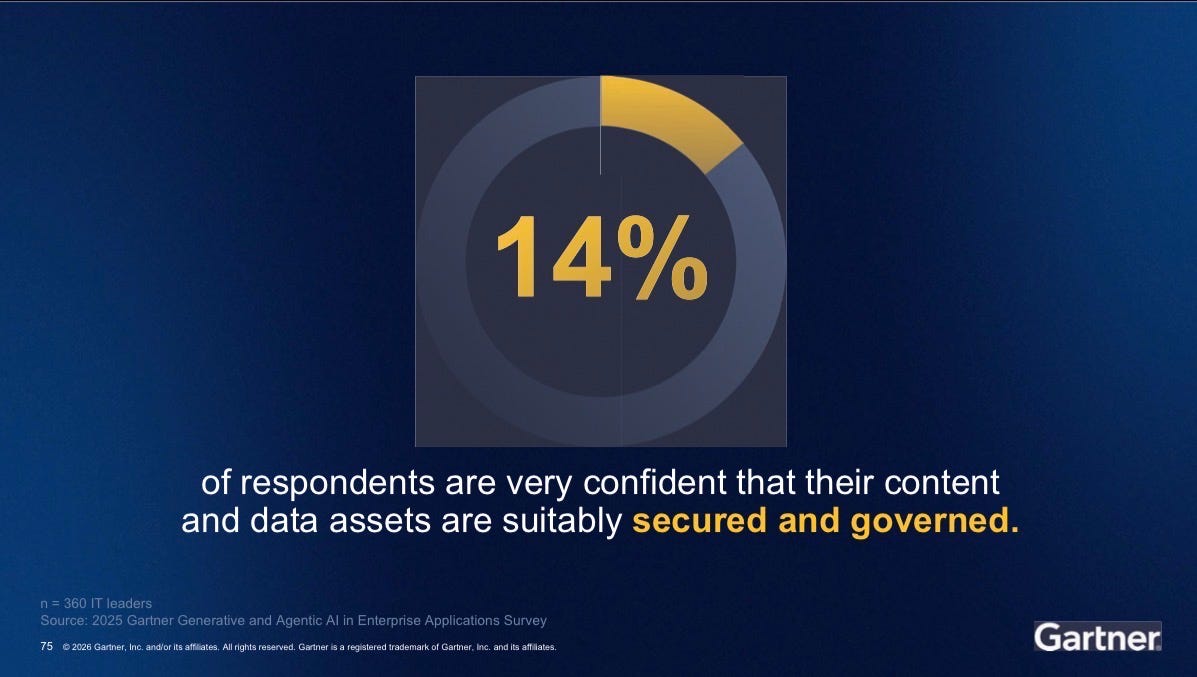
14% are confident their data is secured and governed.
44% of organizations implemented a semantic layer in 2025. 48% plan to by 2027.
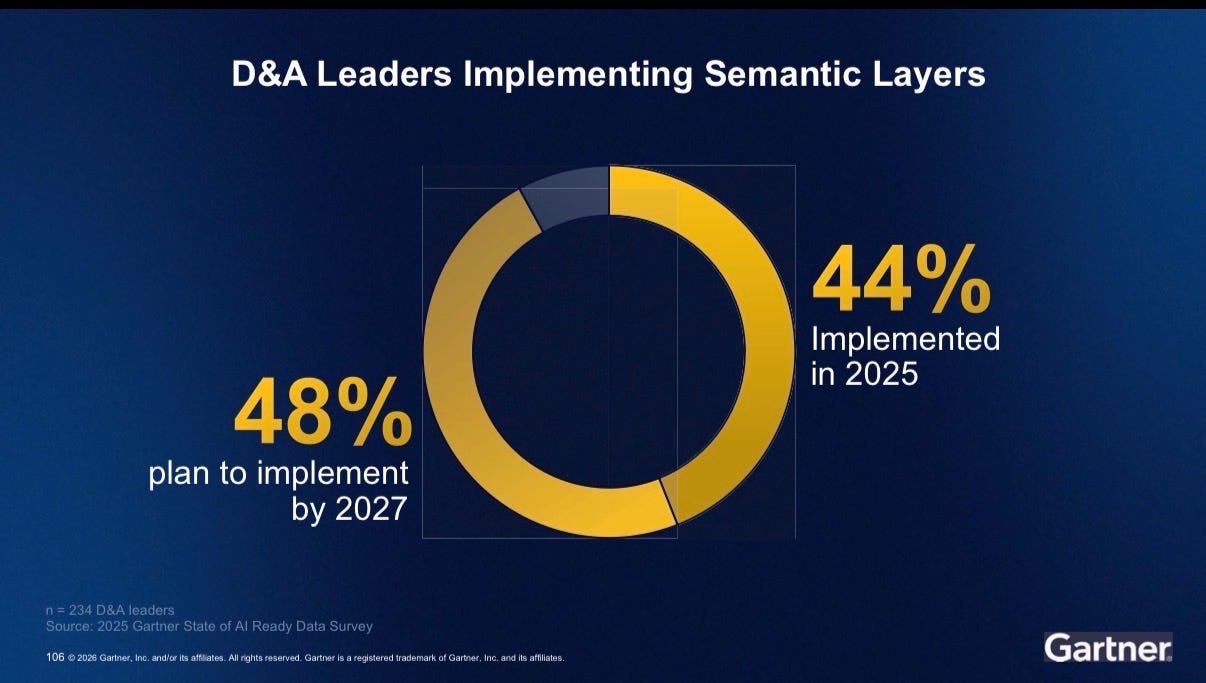
Let that sink in. Half of organizations are building semantic layers. One in seven has their governance in place. We are building on sand and calling it AI ready data. The ungoverned semantic layer is the new ungoverned data lake. We are about to make the same mistake again, just one layer up the stack.
Semantics Is No Longer a Niche Topic
If there was one theme that ran through every session, every analyst conversation, and every dinner table discussion, it was semantics.
Gartner said it plainly: semantics break the barrier to providing AI agent-ready data. Anthony Mullen went further: by 2030, universal semantic layers will be treated as critical infrastructure, right alongside data platforms and cybersecurity. Budget for semantic capabilities is non-negotiable.

But here is the part people are not talking about enough: vendor lock-in around semantics is real and it is coming. We did this with data. We ended up with a dozen point solutions, painful integrations, and fragmented everything. We are about to do it again with semantics if we are not intentional about portability and standards.
The answer is not one more proprietary semantic layer. The answer is a coordinated, federated approach and as Robert Thanaraj said “interoperability is key”. Master your semantics in one place. Expose them everywhere. Build to standards. Upcoming standards such as OSI is a start but it’s only for BI/Analytics semantics. For ontologies, there is a need to look into RDF and OWL
The Intelligence Capability Stack — But Flip It
Carlie Idoine presented a solid maturity model, the Intelligence Capability Stack, showing how organizations progress from AI Cautious to AI Opportunistic to AI First. The layers go from information at the bottom up through context, intelligence, and interaction to outcomes at the top.
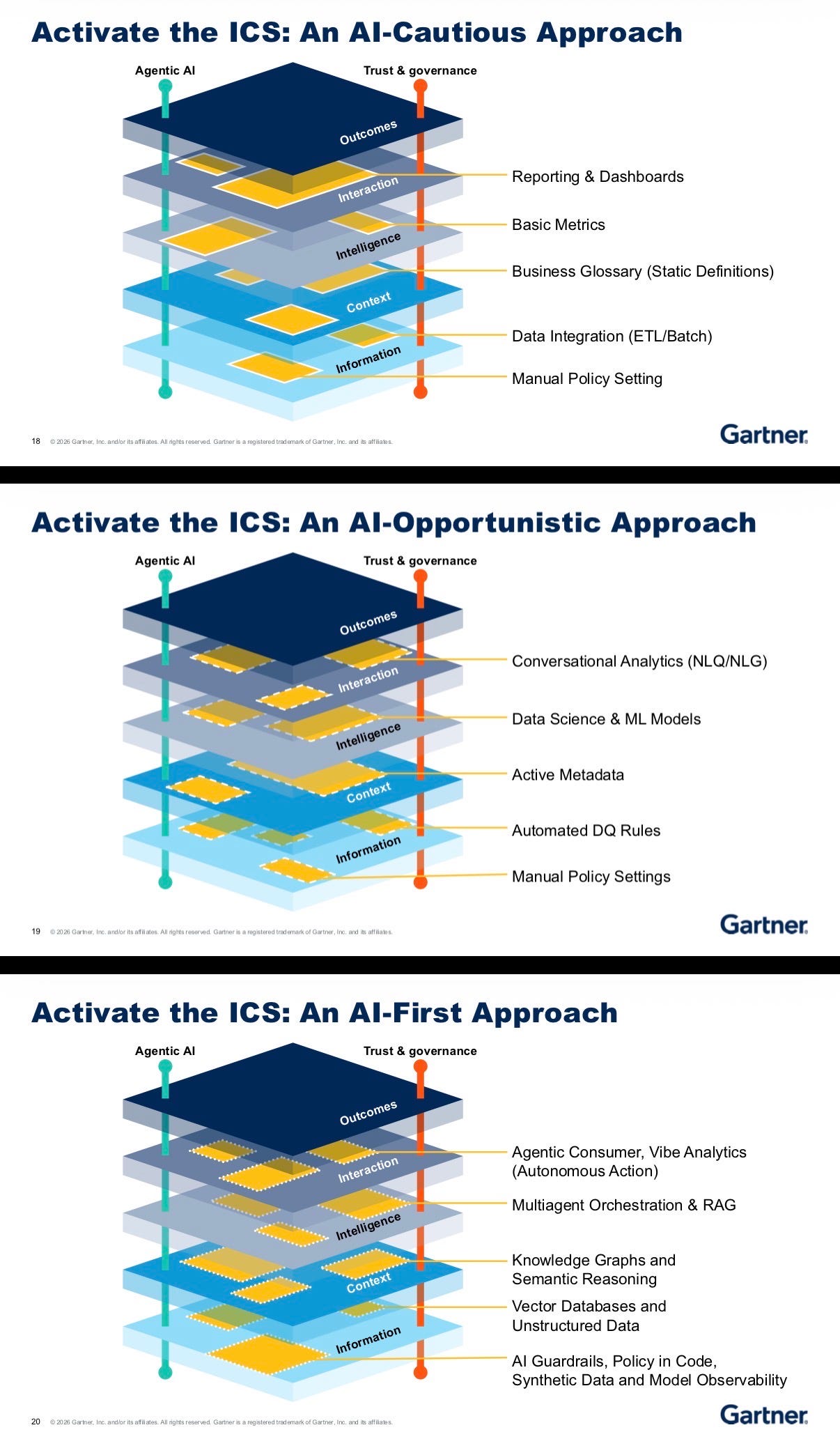
The framework is right. The presentation was backwards: bottoms-up, starting with data and technology. Classic technical thinking.
But companies do not have a data problem. They do not have an intelligence problem. They have a work problem.
We must start explaining these frameworks starting from the top. What outcome do you actually need to achieve? What interaction or action drives that outcome? What intelligence supports that decision? What context is required? And only then — what data powers it all?
Flip the stack. Outcomes first. That is where the value lives.
Data Products Are Not Optional Anymore
Amy Lenander, CDO of Capital One, made this clear: getting data products off the ground was one of her highest-leverage achievements. Because everything builds on top of it. New ERP rollouts. Marketing transformation. AI models. It all sits on that foundation.
The data product is the authoritative source for AI agents. Not a data lake. Not a raw table. The curated, defined, governed data product.
And this line was music to my ears: “We have a number of ontologists. It’s a legit role.”
Yes. It is.
The Data Product Manager is definitely an emerging role: someone obsessed with making data usable for the business. They sit at the gap between the consumer who needs data for a business process and the producer whose primary job generates data others need. That bridge is the job. Data stewards will evolve into this role over time, with AI helping them manage more products than any human could alone.
On Governance: Stop Using It as a Clutch
Only 14% of organizations are confident in their data governance. Governance comes up as a reason things could not get done.
Here is an honest take I heard: too many data leaders use governance as a clutch. A way to say “we can’t do that.” If governance is hard, that is not a reason to stop. That is the problem to solve.
Governance should be embedded in engineering, not bolted on as a blocker. Policy as code is the direction.
AI governance, D&A governance, and corporate governance need to stop living in separate silos and start being harmonized.

Decision Governance, who owns the decisions AI is making, and who is accountable when something goes wrong, is the most underrated trend Gartner called out this year. It is coming whether you are ready or not.
On Data Catalogs: TJ Craig Said What Needed to Be Said
The least valuable way to start with data cataloging is with technical metadata. Stop doing that!
Focus on data flow instead. I call this the Iron Thread approach: identify the outcome you need to achieve, find the minimal data and semantics required to get there, and that is your thread. Then expand from there.
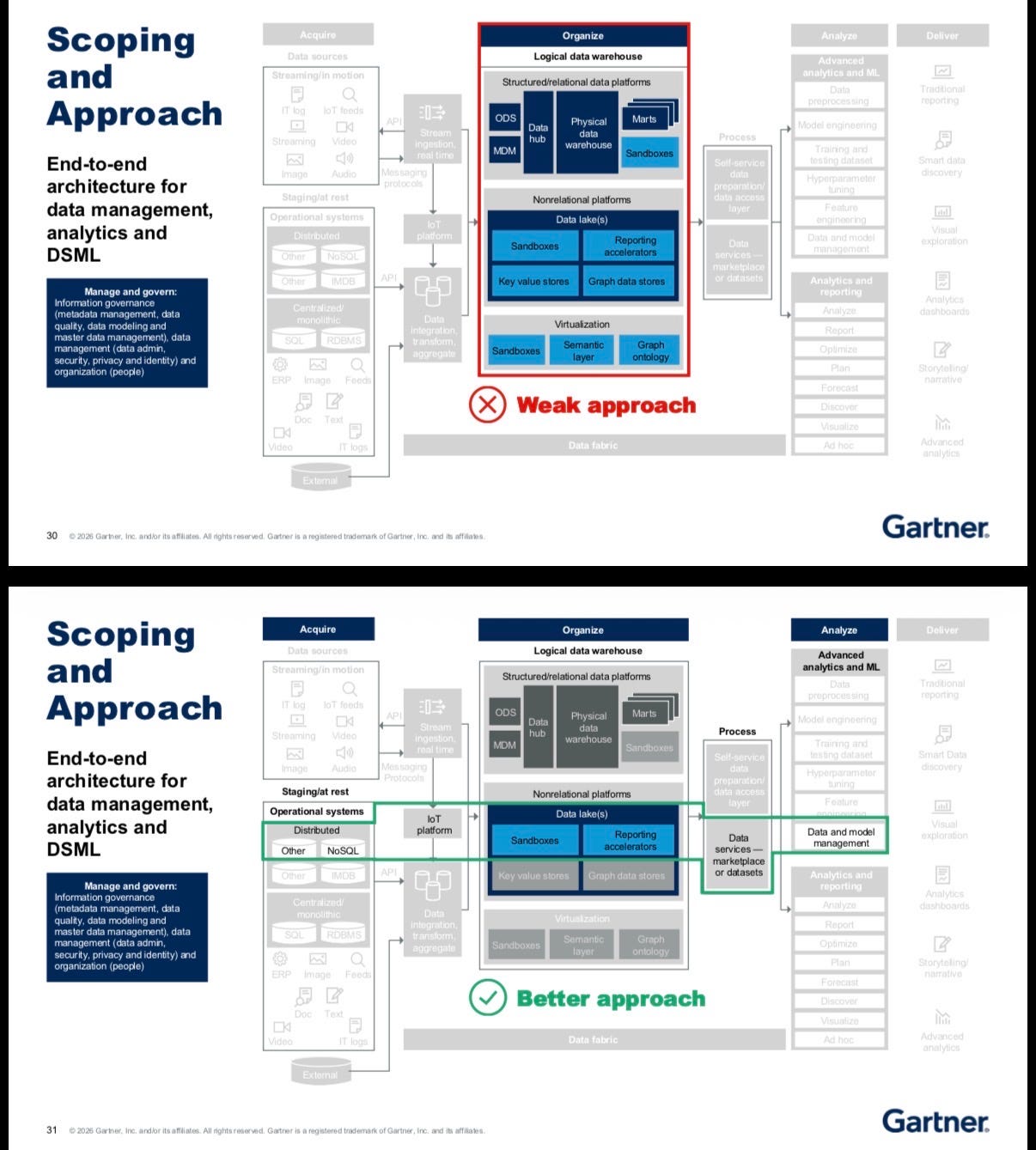
Cataloging is a skill. It comes from knowledge management. It requires understanding taxonomies, ontologies, controlled vocabulary, and standards. The industry has massively underinvested in enablement here, and it shows.
And if you want a best practice that almost nobody follows: create a metadata application profile, the way library science has done for decades. Use Dublin Core. Use DCAT. Build on standards that were designed to last.
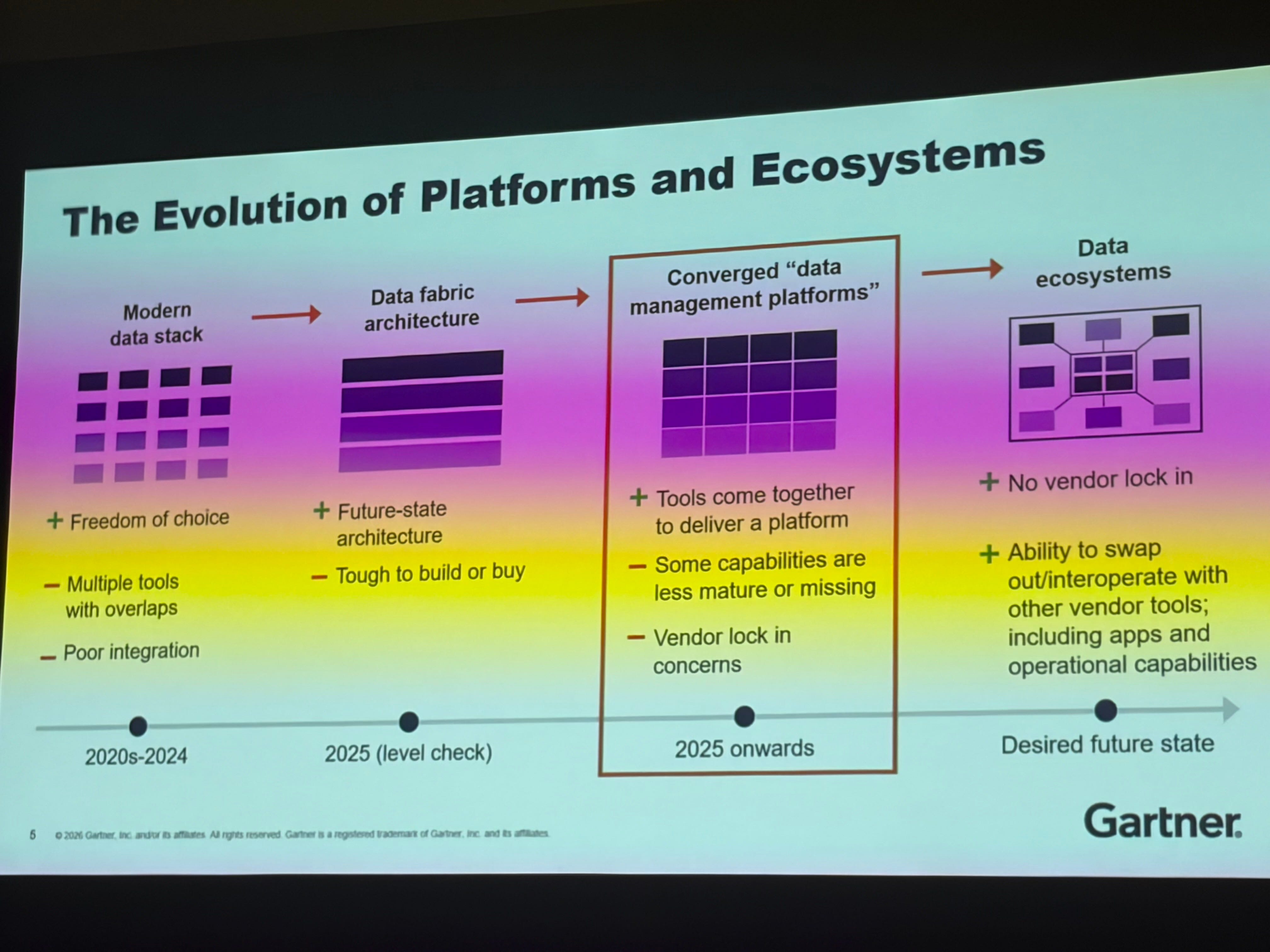
The Platform vs. Point Solution Debate Is Over
Robert Thanaraj said it directly: stop investing in point solutions. They are disappearing. They are becoming features that will be absorbed by platforms.


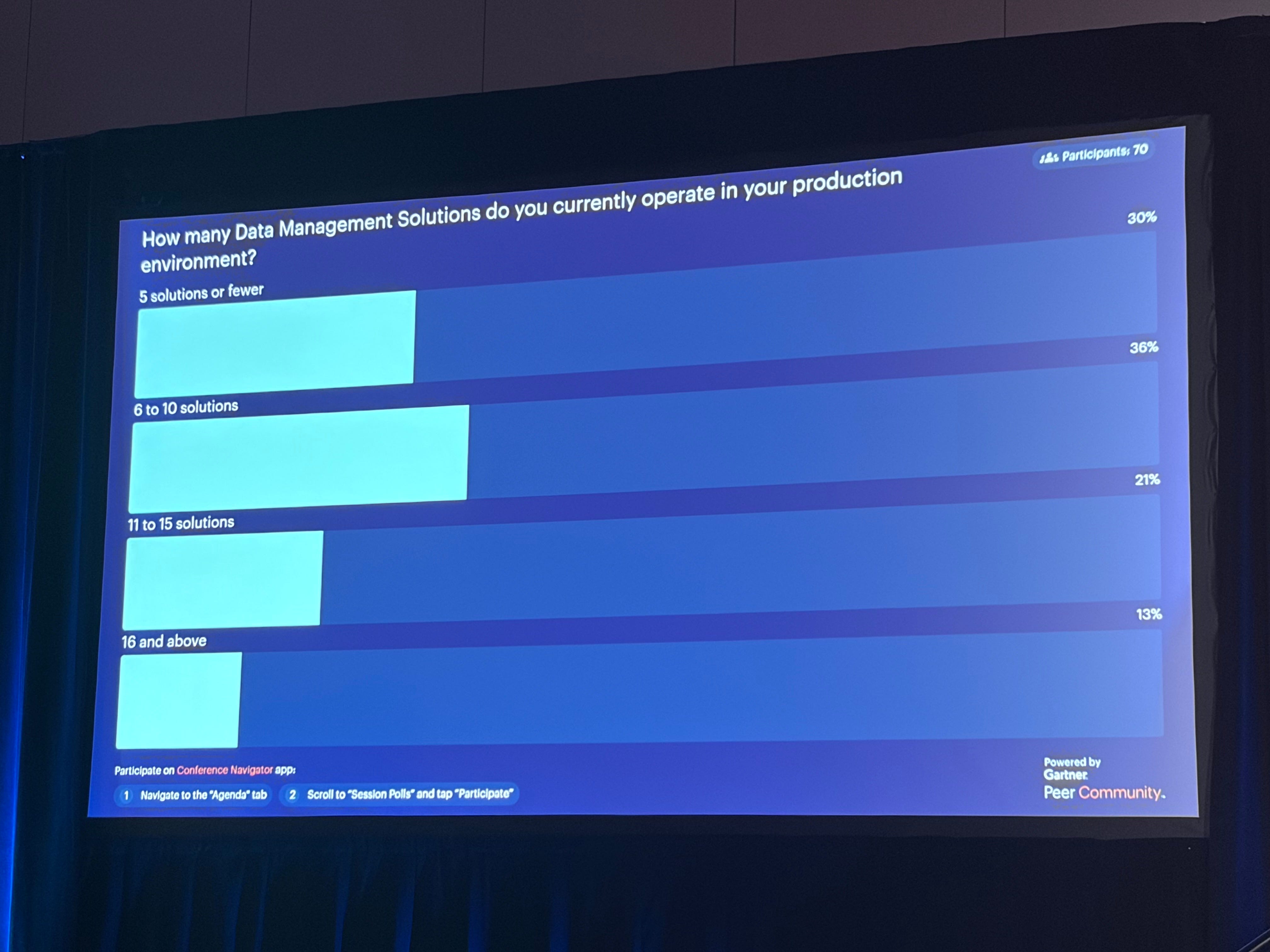
The average enterprise has over a dozen data management solutions. That is not a portfolio, that is a mess! And that is not solving business problems.
The target is one processing control plane. You can have multiple persistence layers. But the fragmentation has to stop.

The signal from analysts and practitioners is consistent.
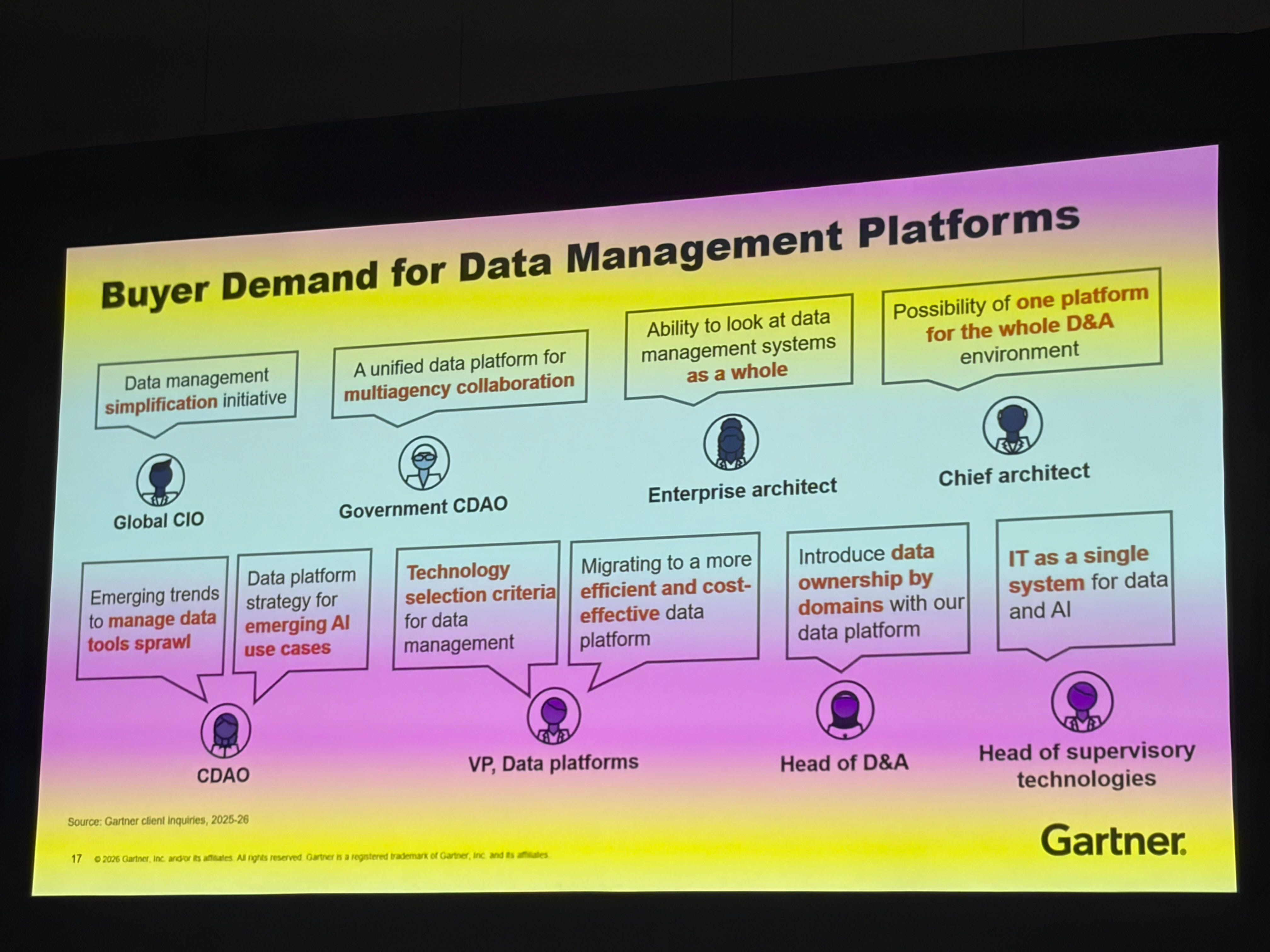
The open question is what happens to all the customers who are mid-contract with point solutions when their terms expire. That transition is coming.
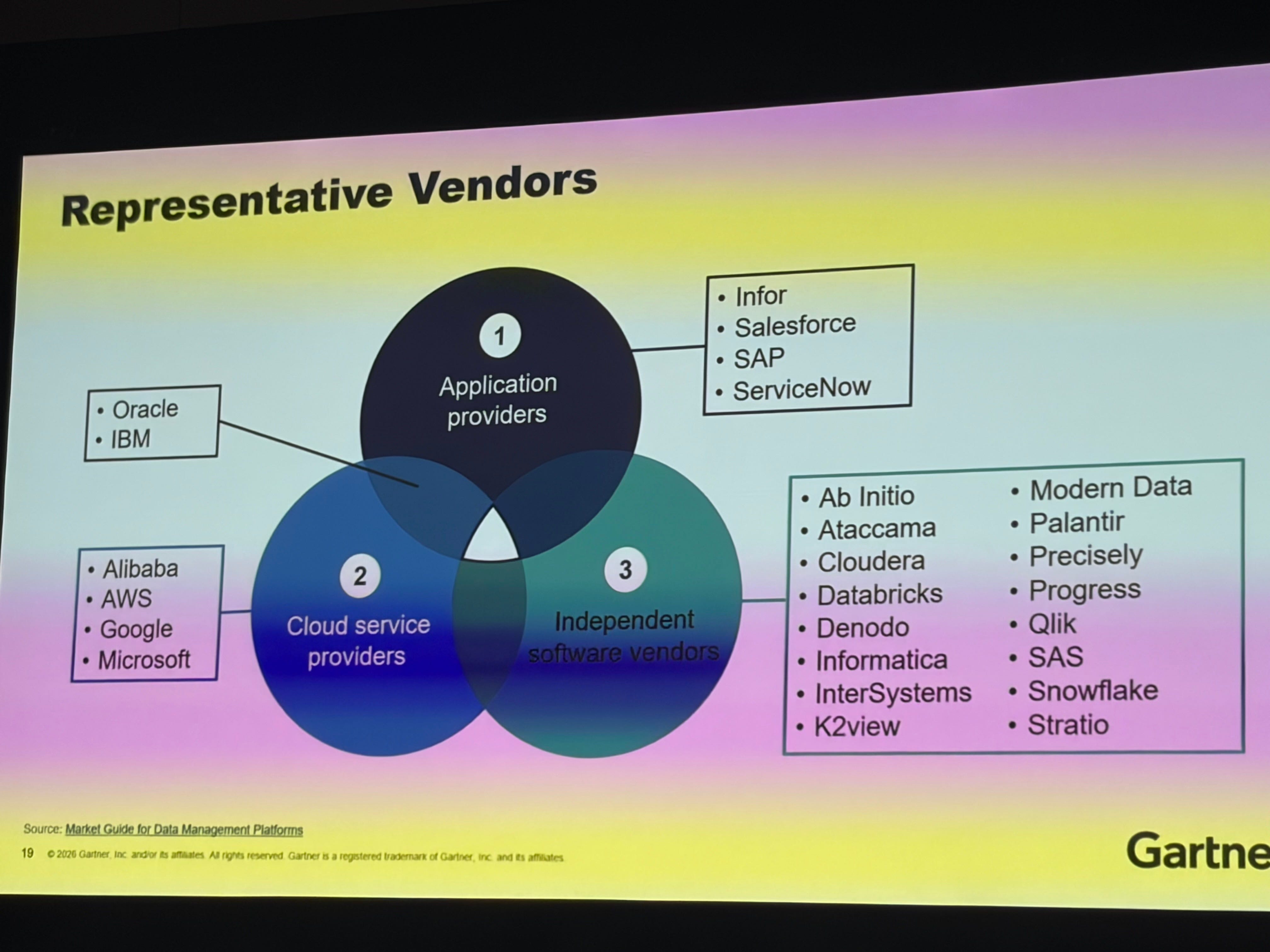
The Bottom Line
Context is king. Or queen. Context carries the crown… however you want to say it.
The organizations that will win are the ones that stop chasing AI demos and start building the foundations that make AI actually work: governed data products, portable semantics, federated context, and a clear line from data to outcome. I’m stating the obvious over and over again.
The foundations are not glamorous. They never were. But everything else is built on top of them. And right now, most organizations are building on sand.
Thank you Juan!
This is brilliant. Juan, spot-on on semantics scaling to 48%, but the rush to portability risks new lock-in if federated layers embed proprietary context (e.g., GraphRAG caching). Orgs need substrate identity (like my DSIL™) first for true sovereignty: on-prem wrappers + standards (OSI/RDF) before agents. Seen this trap in fintech claims scaling.