Trip Report: International Semantic Web Conference (ISWC2025)
Summary of the things I learned at the 2025 International Semantic Web Conference, my scientific home.

ISWC (International Semantic Web Conference) is my scientific home. This is where I grew up academically and scientifically. I first attended in 2008, and I’ve been going every single year since (I only missed 2010). So for me, ISWC is always a homecoming, a chance to reconnect with longtime friends and colleagues, meet new faces and upcoming researchers, and see where the puck is heading in this space.
For those unfamiliar, the International Semantic Web Conference has been the gathering point for this research community for almost 25 years. It’s where we collectively explore what it means to integrate data and knowledge at scale. The scientific results from this community have led to what is now commonly known as Knowledge Graphs. So if you want to know where the puck is heading in the knowledge graph space, this is the place to be!
The conference brings together people from all corners of AI (machine learning, logic, knowledge representation and reasoning, NLP), databases, HCI, and many other parts of computer science. It’s truly a diverse and eclectic community.
This trip report is organized around the things that caught my attention, a non-exhaustive list by design. Five days of ISWC throws an overwhelming amount of information at you, so what I’m sharing here is more of a curated reminder of topics I want to dig deeper into. There’s simply not enough time to cover everything.
The good news: You can access all the papers for free. Everything is open and available to explore. Many talks were recorded and will be available soon.
This year, I was also part of the organizing committee as the Workshops & Tutorials co-chair together with Blerina Spahiu. We introduced something new: Dagstuhl-style workshops, inspired by the Dagstuhl seminars. No presentations, just focused discussion and collaboration. I think they were a real success. Huge kudos to the entire organizing committee; you all pulled off a fantastic event.
So with that, here we go. This is my ISWC trip report and the highlights that stuck with me.
I gave a keynote titled “If knowledge is power, who governs it?” at the Knowledge Base Construction from Pre-Trained Language Models workshop and also participated in the panel Reimagining Knowledge: The Future and Relevance of Symbolic Representation in the Age of LLMs. My main message was two-fold: 1) we need to rethink how to do knowledge engineering scalably and if we succeed at capturing knowledge at scale, 2) we need to think about how to govern all the different versions of truths that we will capture.
I was honored to be on a panel with Natasha Noy, Tara Raafat, Elena Simperl and moderated by Ramanathan V. Guha, I started by reminding the audience that the essence of the Semantic Web community and everyone attending ISWC is to research how to manage knowledge at scale in a distributed world.

Two main challenges stand out for me. First, knowledge engineering is returning to many of the best practices from the late 80s and 90s, but we now need to uplift those approaches to modern tools—LLMs, new paradigms, the changed world we live in (balance of centralization and decentralization). My prediction is that we will soon have many more ways to generate much more knowledge, which means we’ll need strong knowledge governance. We will be shifting from a data-first world (collect more data) to a knowledge-first world (manage the knowledge itself).
So: where does this knowledge live? My framework is that knowledge exists at multiple layers:
Business: business and domain knowledge, represented through glossaries, taxonomies, ontologies.
Technical: metadata about where data resides (the data-first world).
Mappings: the transformations that connect data to business meaning. These mappings are what ground semantics in actual data.
We need far more automation in knowledge engineering. Historically, in the 80s and 90s it was extremely manual. Today the challenge is capturing the diversity of knowledge:
in business processes (whether written or implicit),
in people’s heads,
in application code,
in ETL pipelines,
in dashboards and BI tools,
in data itself,
and of course in text (which has been the focus of most work on automatically building knowledge graphs)
The question becomes: what level of rigor is required to manage all this? Historically, we used rigid, formal approaches. We now may need ways to work with less rigor in some cases and be okay with that. Otherwise, we fall back into an ivory-tower problem. We’ve learned from governance that ivory-tower approaches don’t work.
Our fundamental challenge remains: how do we best manage knowledge? This leads to major research questions:
How do we know if an ontology is “good”? Maybe an ontology is good if the LLM works better with it? That could be the new measure of quality.
What are the incentives for people to participate in knowledge work?
How do we govern knowledge?
How do we create socio-technical systems that support this?
We also need to revisit past knowledge engineering methodologies and uplift them using modern tools like LLMs, and rethink governance methodologies around them. Let’s not forget: LLMs are just a tool.
We may also need new knowledge representation and reasoning paradigms. We’ve always framed this in terms of formal logic, but with new tools like LLMs, what does KR&R look like in this new world?
I also reminded the audience that not everybody is “Google”. For example, Google operates at an enormous scale, with a goal of organizing all the world’s knowledge. Enterprises do not. They want to organize their own internal knowledge, which is much smaller and finite. This is why enterprise needs differ from open-web large scale needs. So while there is a lot of focus on creating knowledge graphs from web text, enterprises ultimately want to extract, integrate, and manage a more bounded set of internal knowledge so they can take action on it. And the core enterprise problem hasn’t changed in 30 years: “put my data together so I can answer questions and take action.”
We also talked about agents. I described two dimensions:
Human-facing vs. autonomous agents:
Human-facing: conversational, chat-style experiences.
Autonomous: sensing, reasoning, and acting independently.
Deterministic vs. non-deterministic agents:
Deterministic: follow governed workflows defined by humans.
Non-deterministic: truly autonomous, improvisational, emergent behavior.
Most real agents will sit somewhere along both spectrums.
Finally, we circled back to what unites the community: the Web. The web is a decentralized information space, and that’s what brings us all together. For me, the exciting part is taking what we’ve learned from the web and applying it to enterprise environments.
Knowledge Engineering
I was very happy to see presentations on knowledge engineering, which is an area that I strongly believe needs more focus.
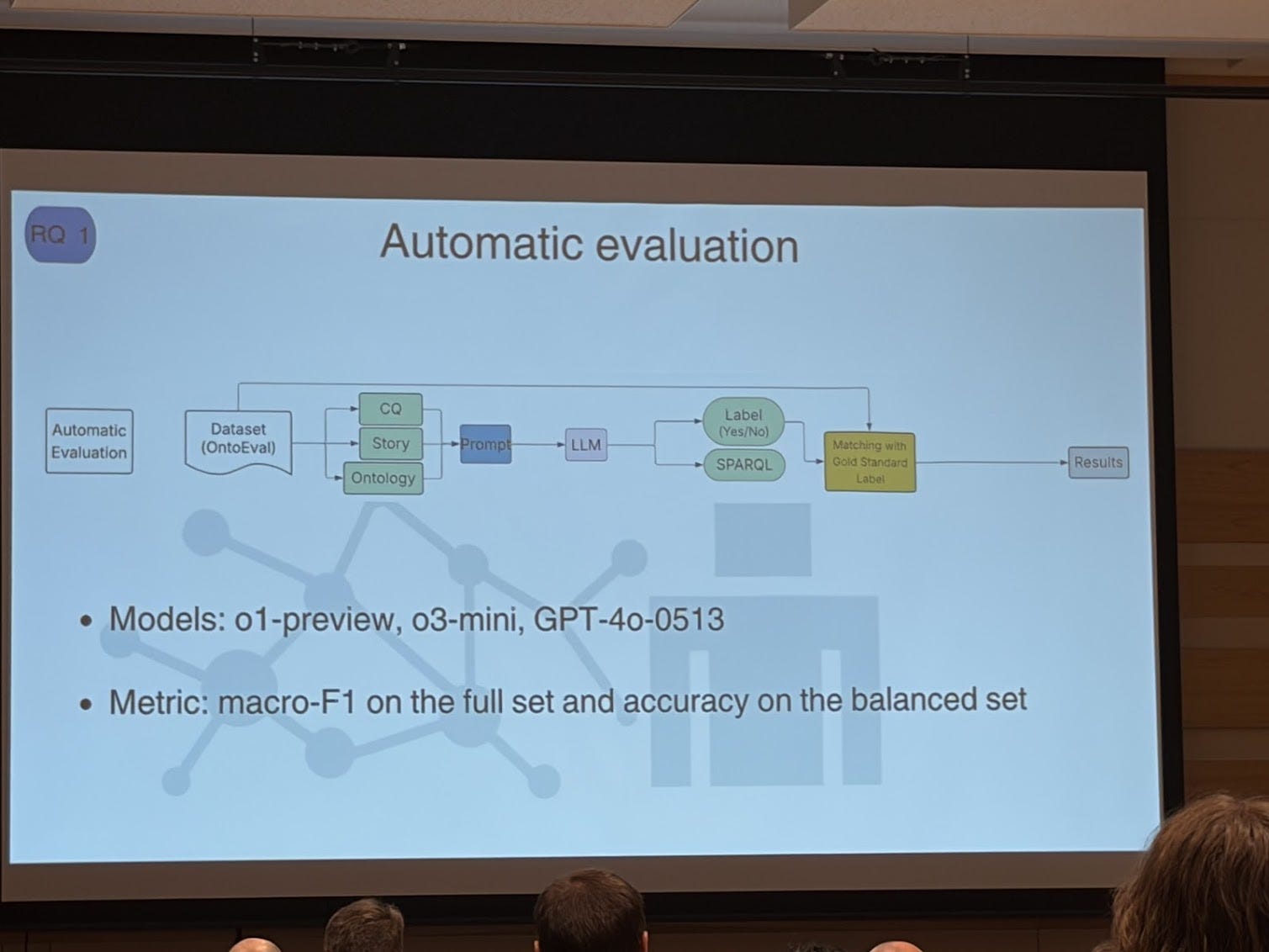
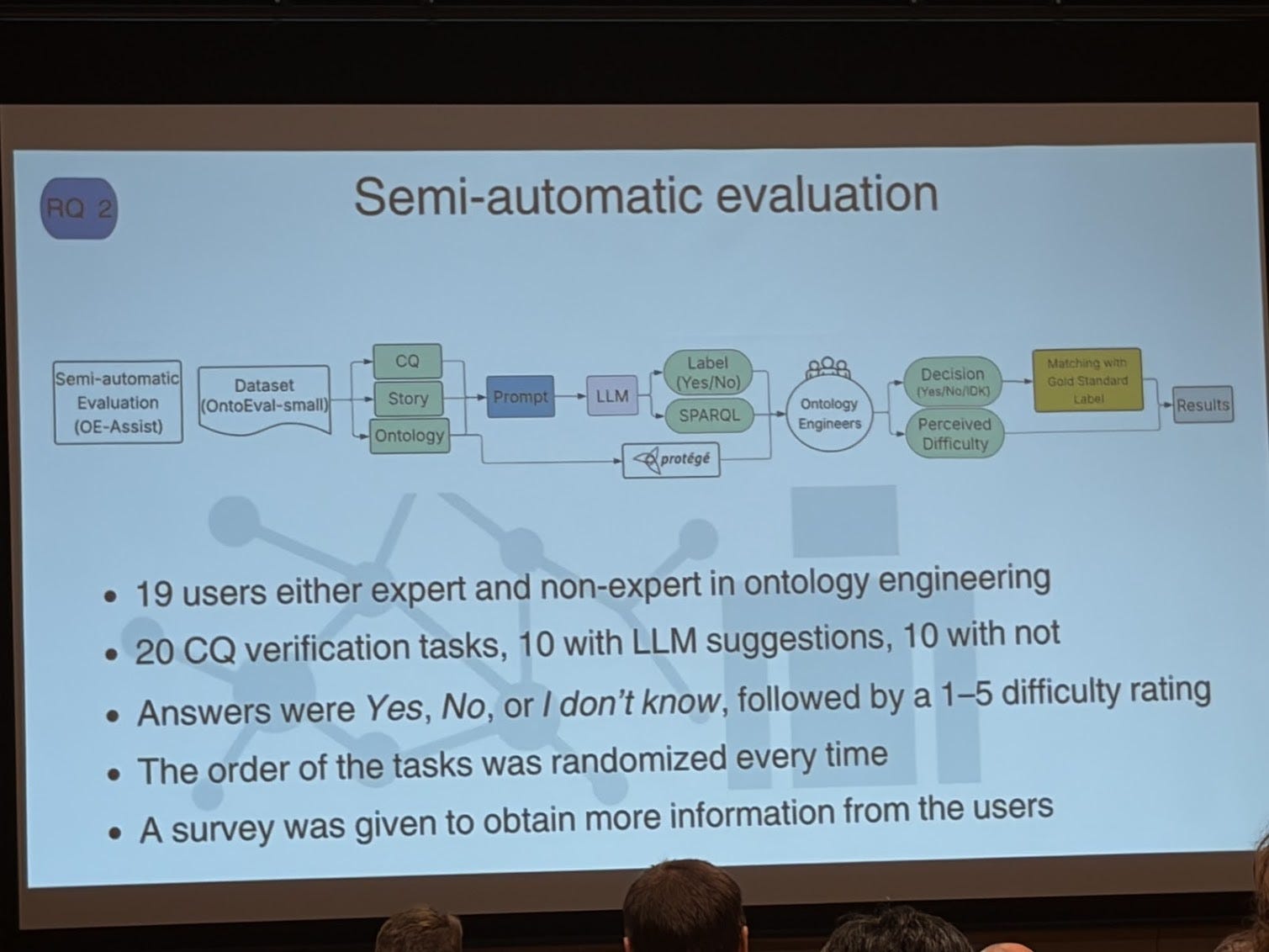
With the increased interest in knowledge graphs and now ontologies, and how LLMs make it easier to create ontologies, the question that will be coming up is how to know if your ontology is “correct”? By verifying if the ontology models the competency questions. So now the question is, can LLMs help us? The paper “Large Language Models Assisting Ontology Evaluation” tackles this problem by asking the following research questions
– RQ1. To what extent can LLMs evaluate ontologies using CQ verification?
– RQ2. To what extent can LLMs assist ontology engineers in evaluating ontologies through CQ verification?


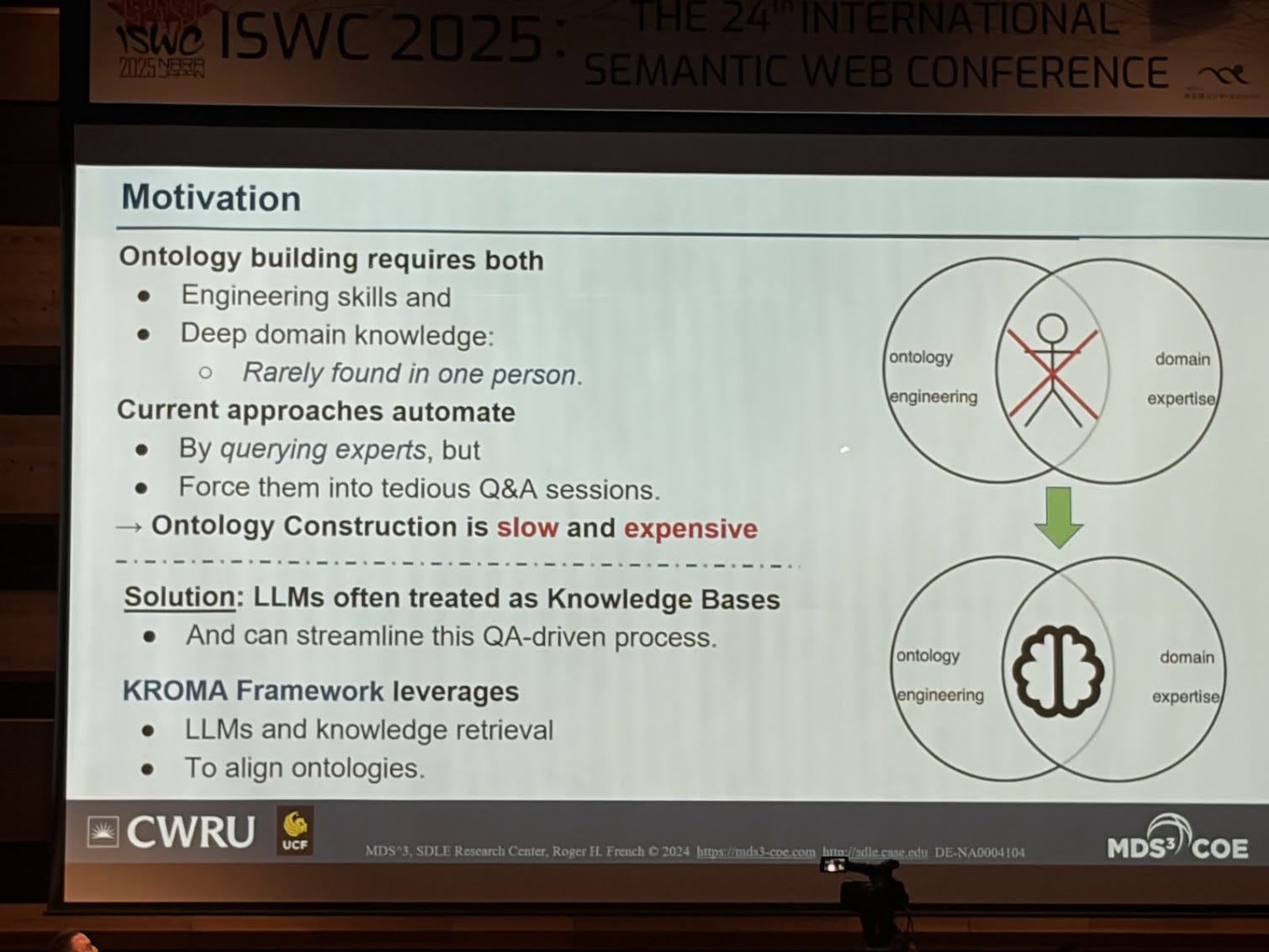
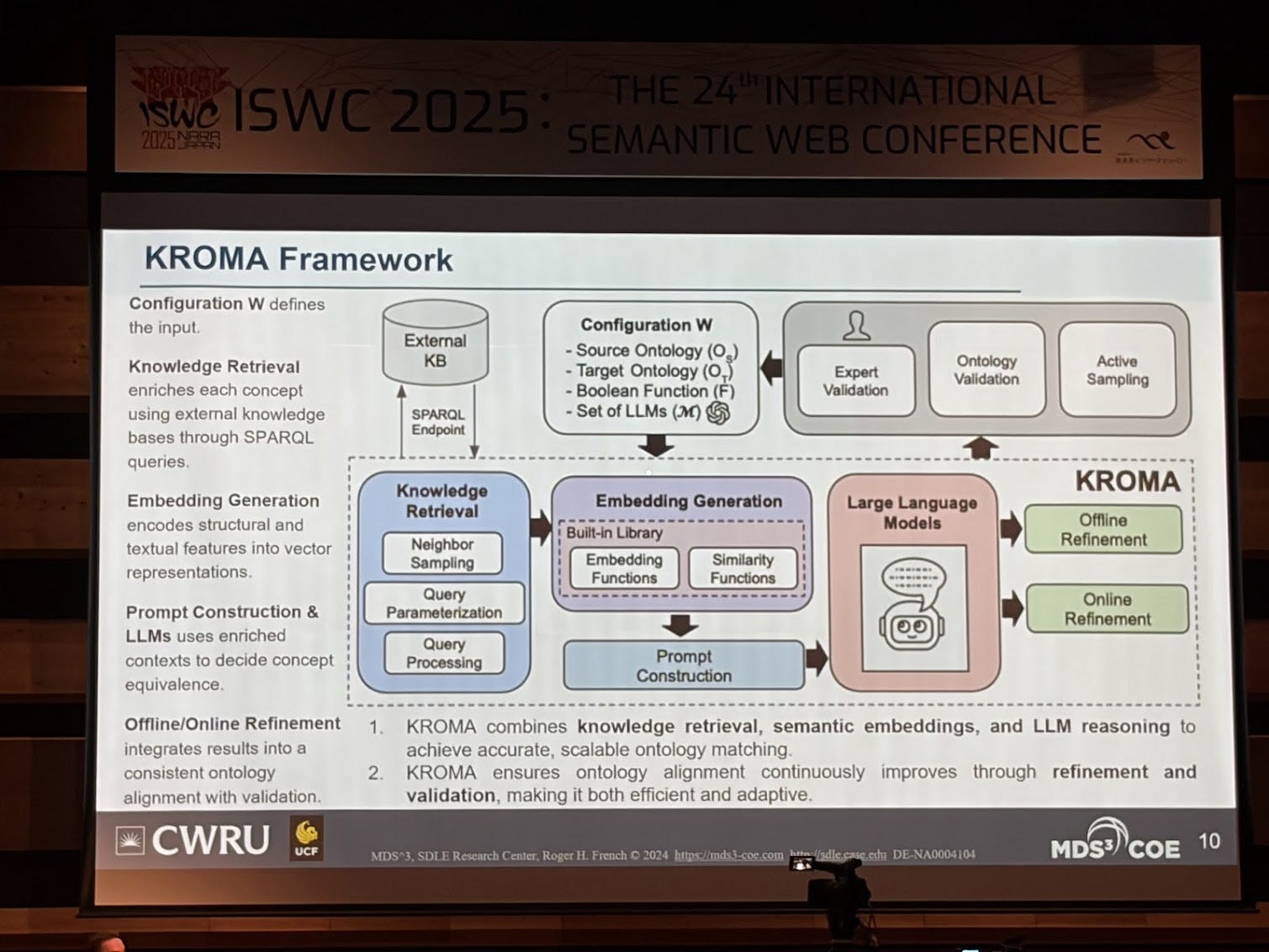
Once you start having multiple ontologies, the question is how do you start aligning and matching them. This has also been very well trotted territory for decades (see the Ontology Matching Workshop and all their papers, and also SemTab: Semantic Web Challenge on Tabular Data to Knowledge Graph Matching). I really liked the paper “KROMA: Ontology Matching with Knowledge Retrieval and Large Language Models” because it’s an example of what I’m calling for: rethinking knowledge engineering by using the new tools that we have today (i.e. LLMs). Note several papers on this topic were also presented at the ontology matching workshop which I need to dive into.



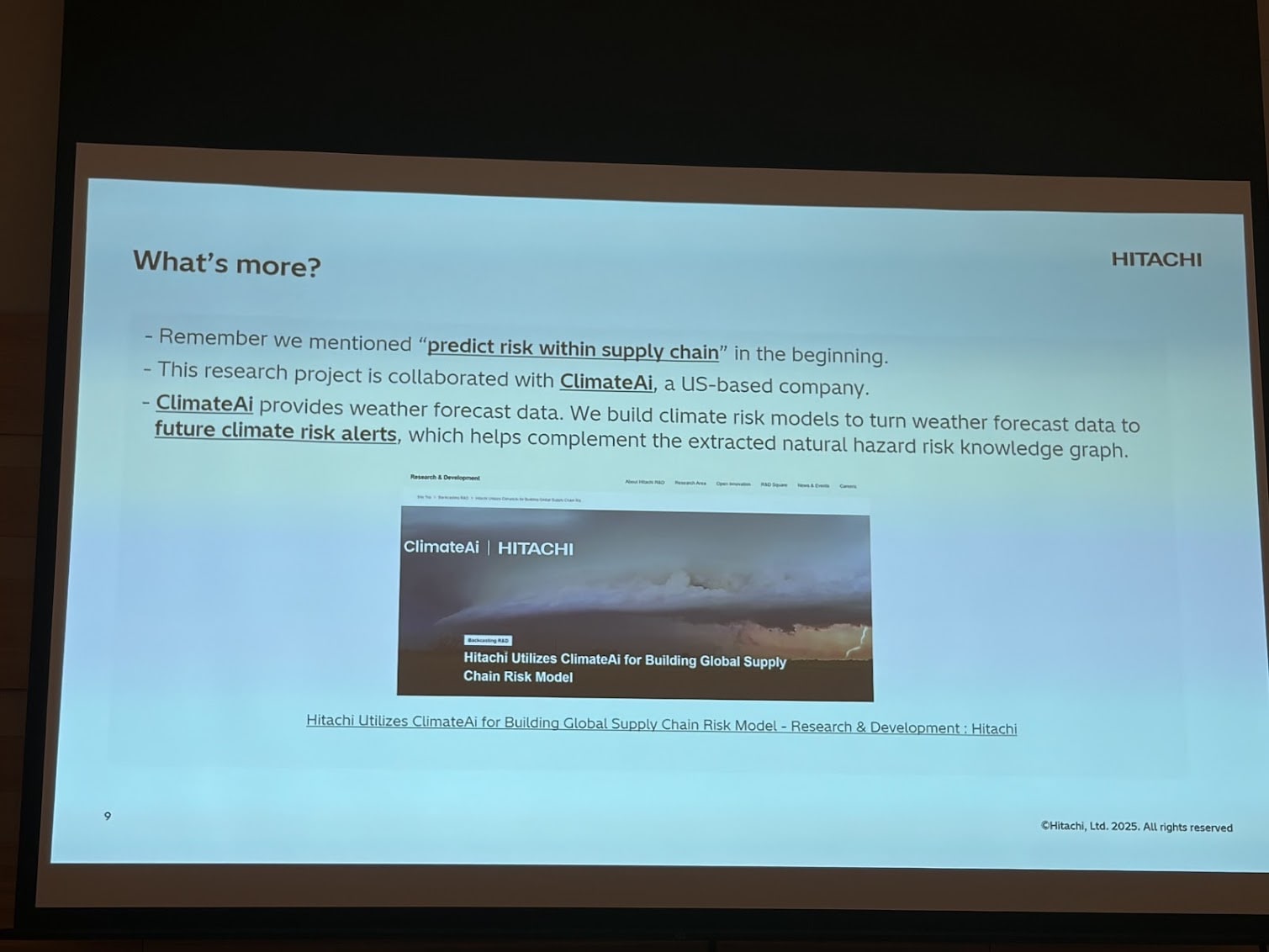
Once you have an ontology, what can you do with it? Hitachi presented “Empowering Supply Chain Risk Monitoring with Ontology-Guided Knowledge Graph Extraction by LLMs” on how they are using semantic technology to build a resilient supply chain starting off by predicting risk within a supply chain.
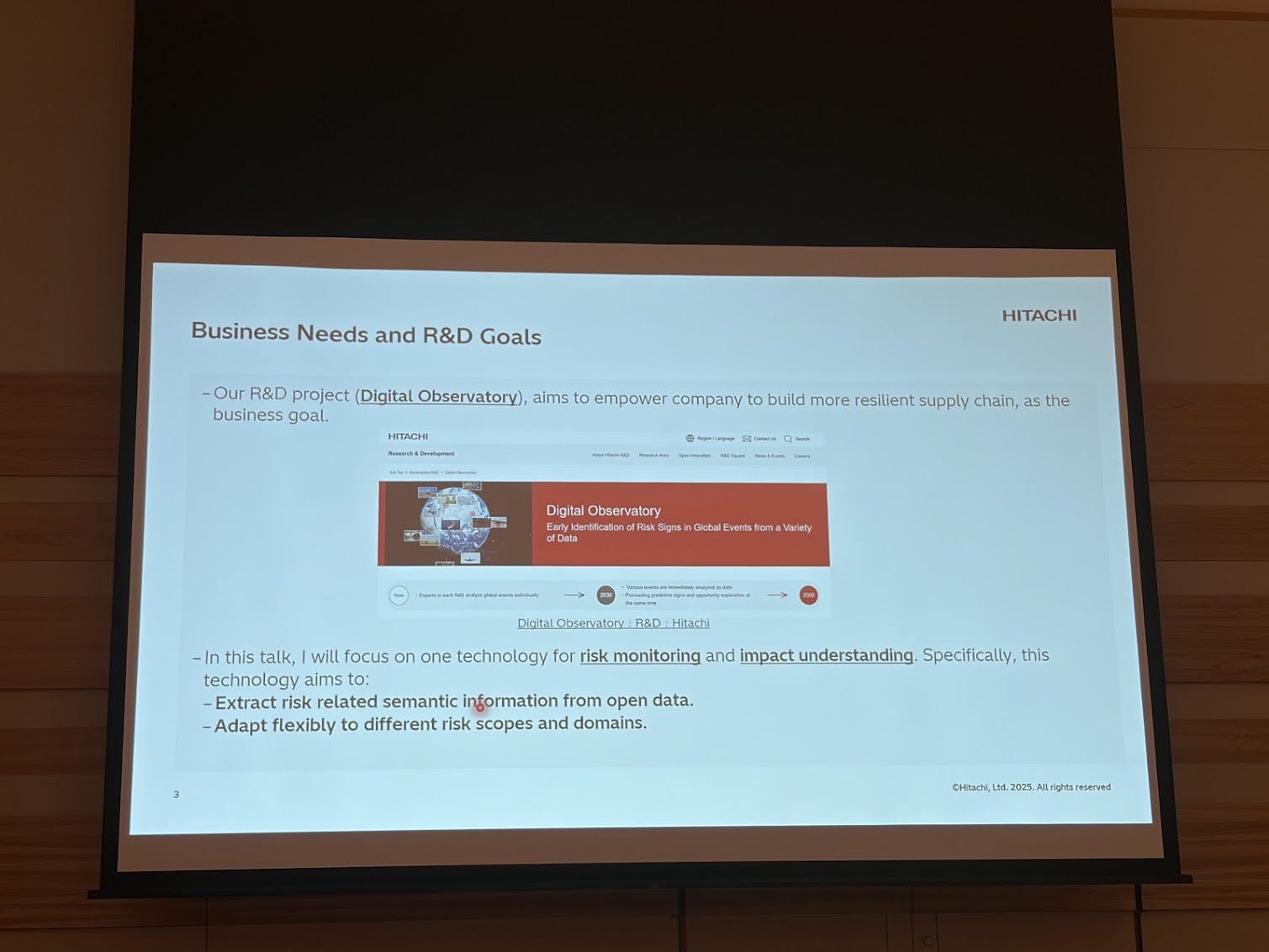
This is an example where the ontology itself is a valuable artefact. By modeling first your domain of interest, it’s used to tell the LLM what needs to be extracted in order to create the KG. The input are news articles about natural events that can affect a supply chain.

What I found interesting is that they used an iterative ontology prompting, similar to chain of thought, instead of passing in the entire ontology in the prompt. This led to higher quality knowledge graphs. Devils in the details (not presented because this was an industry presentation) but enough food for thought.

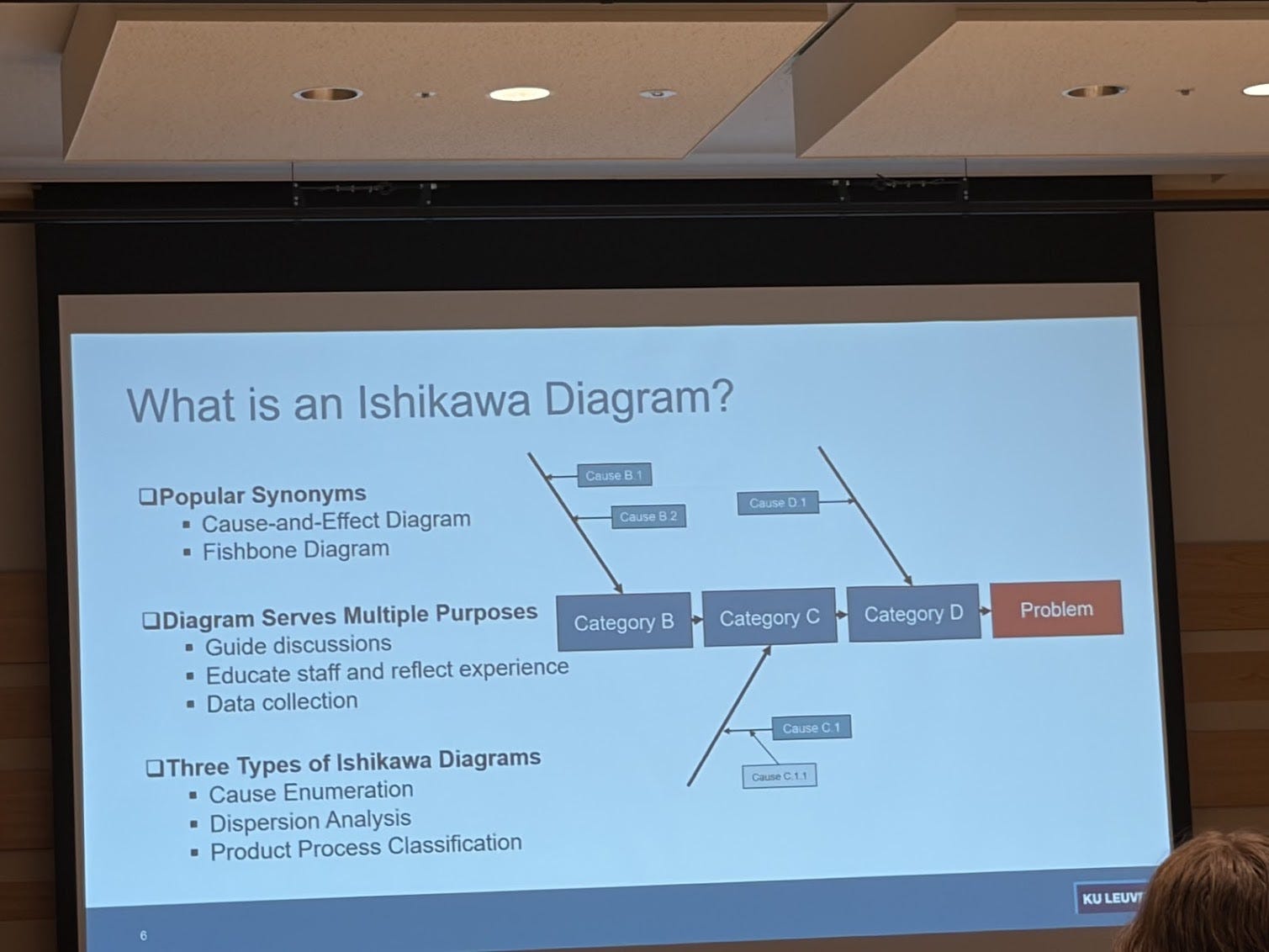
I learned about Ishikawa Diagrams, in the presentation of “A Domain Ontology for Ishikawa Diagrams to Enhance Root Cause Analysis”


A takeaway I’m having is that we (at least I do) need to start thinking much more about combining knowledge engineering with business processes. There are several other scientific areas that focus on business processes; however I believe we need to build more bridges between our scientific areas. Processes (and causation) are going to play a fundamental roll in the successful deployment of AI agents that can truly drive change in an organization. Otherwise, the AI agents will be focused on productivity gains.
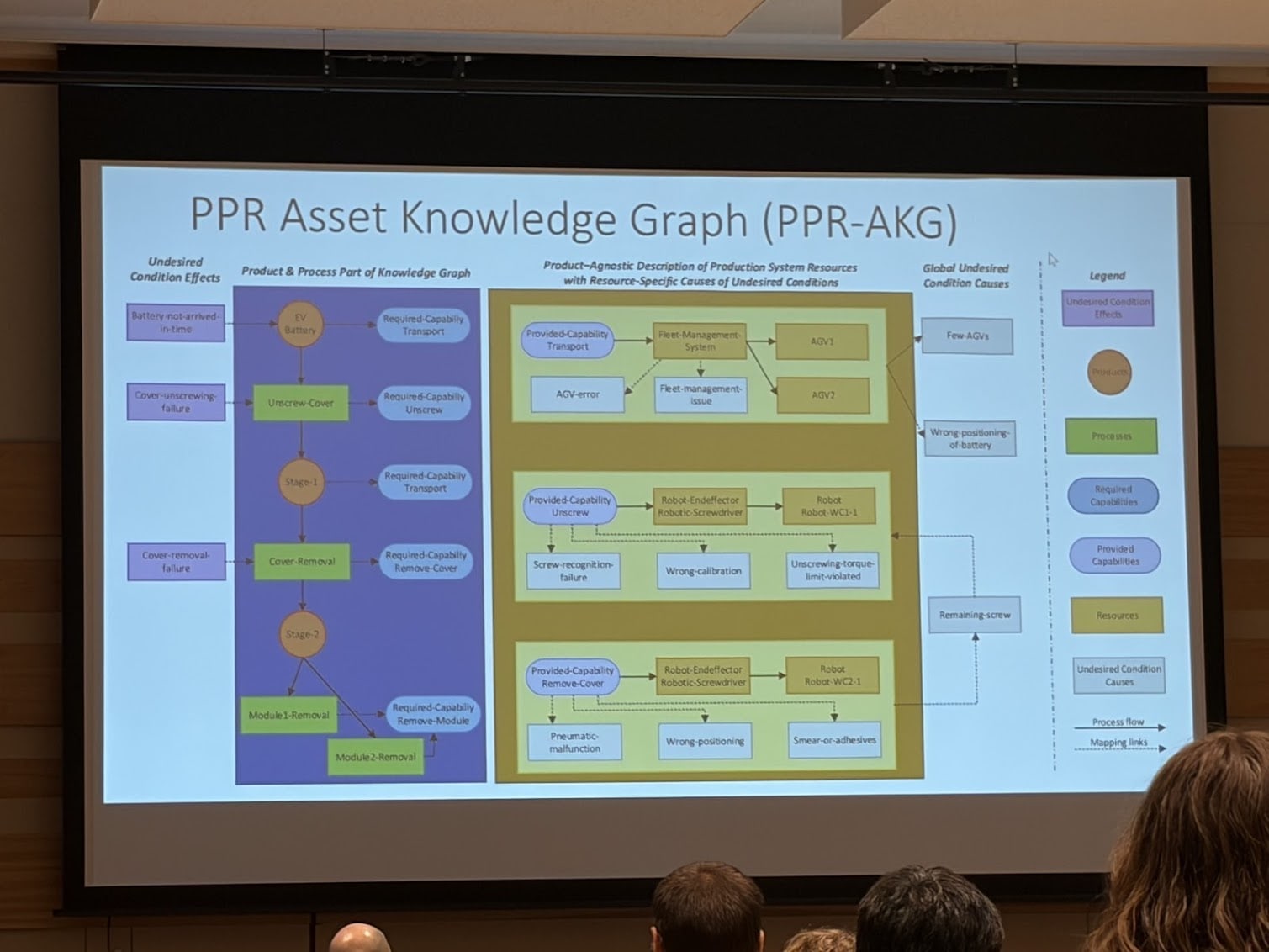
And talking about processes, there was an industry presentation “Mitigating Undesired Conditions in Flexible Production with Product-Process-Resource Asset Knowledge Graphs”. They designed a semantic model realizing the product–process–resource (PPR) asset knowledge graph (AKG) that fulfills the following requirements
Model ability to represent flexible Industry 4.0 production of products with highly automated production resources, adopting principles of skill-based engineering;
Model ability to represent undesired conditions relevant for production system engineering in terms of plausible causes and effects;
Support for efficient interaction with human engineers and operators via LLMs/chatbots.




A couple of posters I saw on this topic of knowledge engineering:
This is a must read paper: Knowledge Engineering using Large Language Models


Automatically creating Knowledge Graphs
One of the main topics continues to be automatically creating knowledge graphs, specifically from text. And then continuing with tasks such as link prediction. This has always been a big area in the natural language processing community for years (decades?), so there’s always a lot of work happening. I learned about the startup Lettria from Raphael Troncy and their latest benchmark results for text to knowledge graph. Need to take a closer look.
I also started seeing a couple of presentations where the input is still text, but the focus is on a particular domain, which reduces the problem to something more specific. For example, the paper “From Legal Texts to Structured Knowledge: A Comprehensive Pipeline for Legal Text Summarization”
I am a huge fan of Craig Knoblock’s work. He is a pioneer, not just in knowledge graphs but going back several decades to Intelligent information Systems (IIS). They’re building knowledge graphs around critical minerals. They have all these documents and reports, and inside those reports there’s text, but more importantly there are tables they need to extract knowledge from. So they’ve been building techniques to automatically extract both narrative text and structured table content. In their paper “A Domain-Independent Approach for Semantic Table Interpretation” they present an approach that takes as input a table and an ontology and generates mappings. This has been well trotted territory for years, but what I find novel about this approach is that it takes both concepts and properties and maps them to columns (usually the automated mappings approaches take either a concept or a property) in the table, creates a candidate graph and then prunes it. The limitation is that this is on just one table.

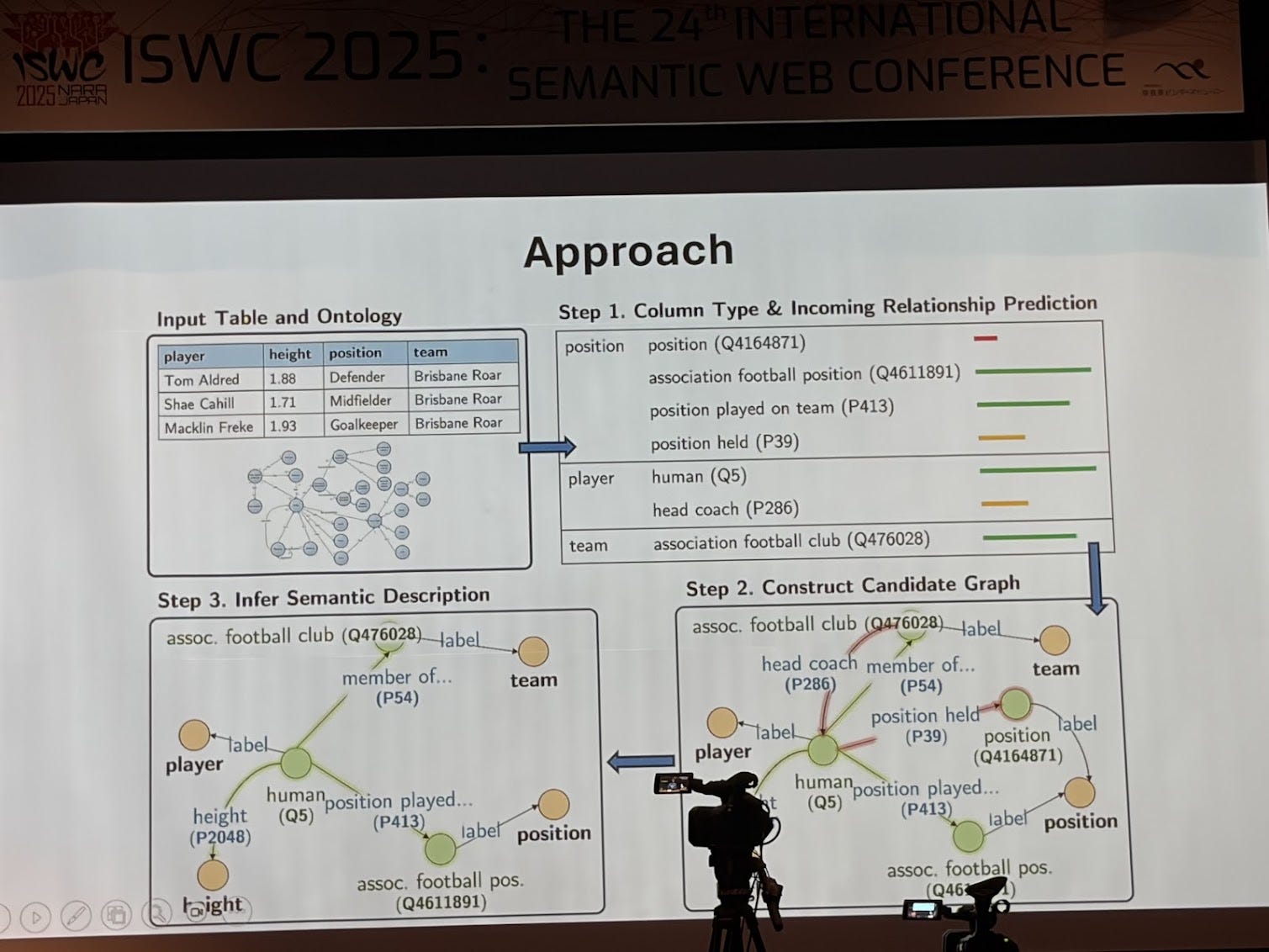
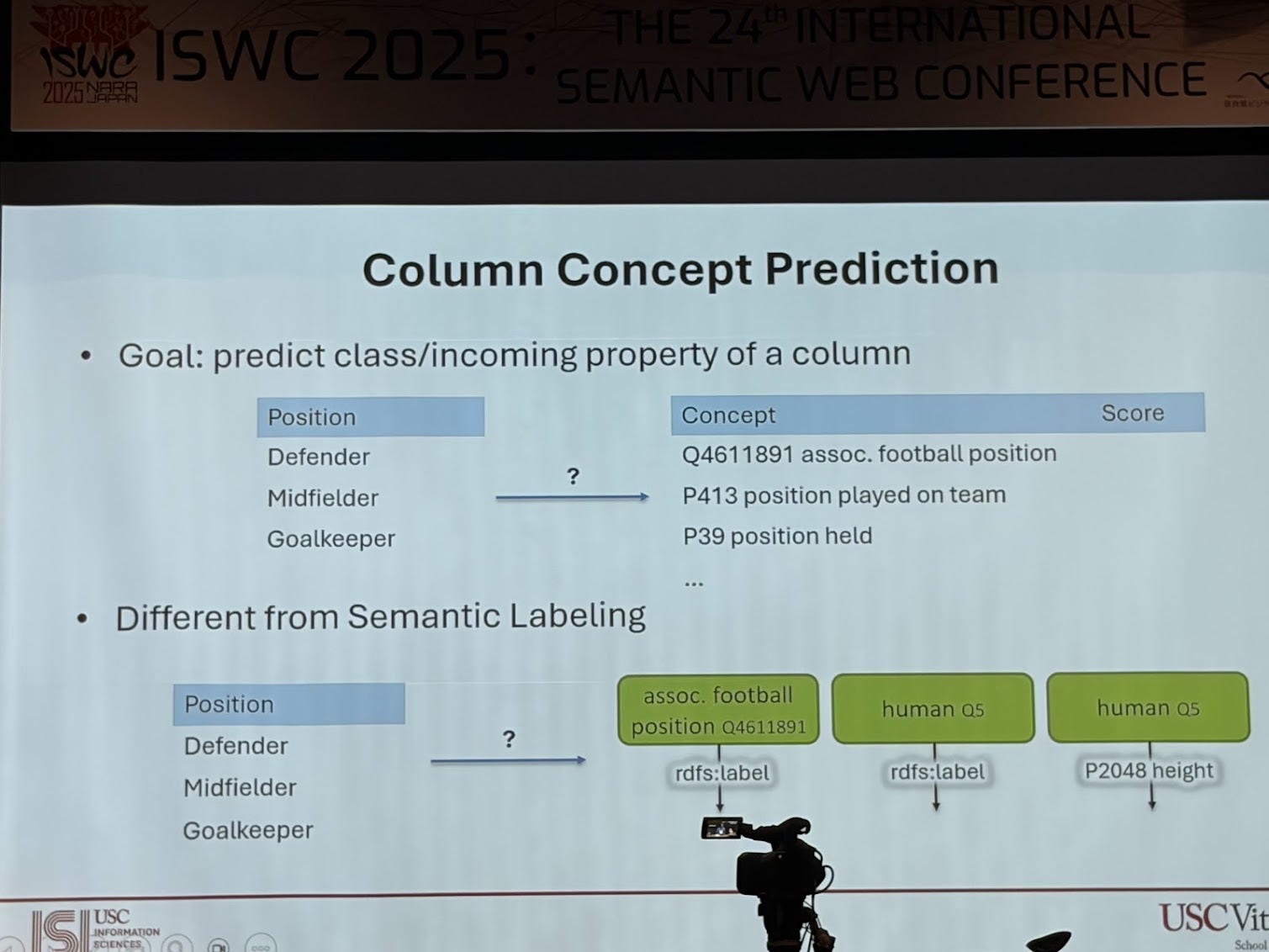
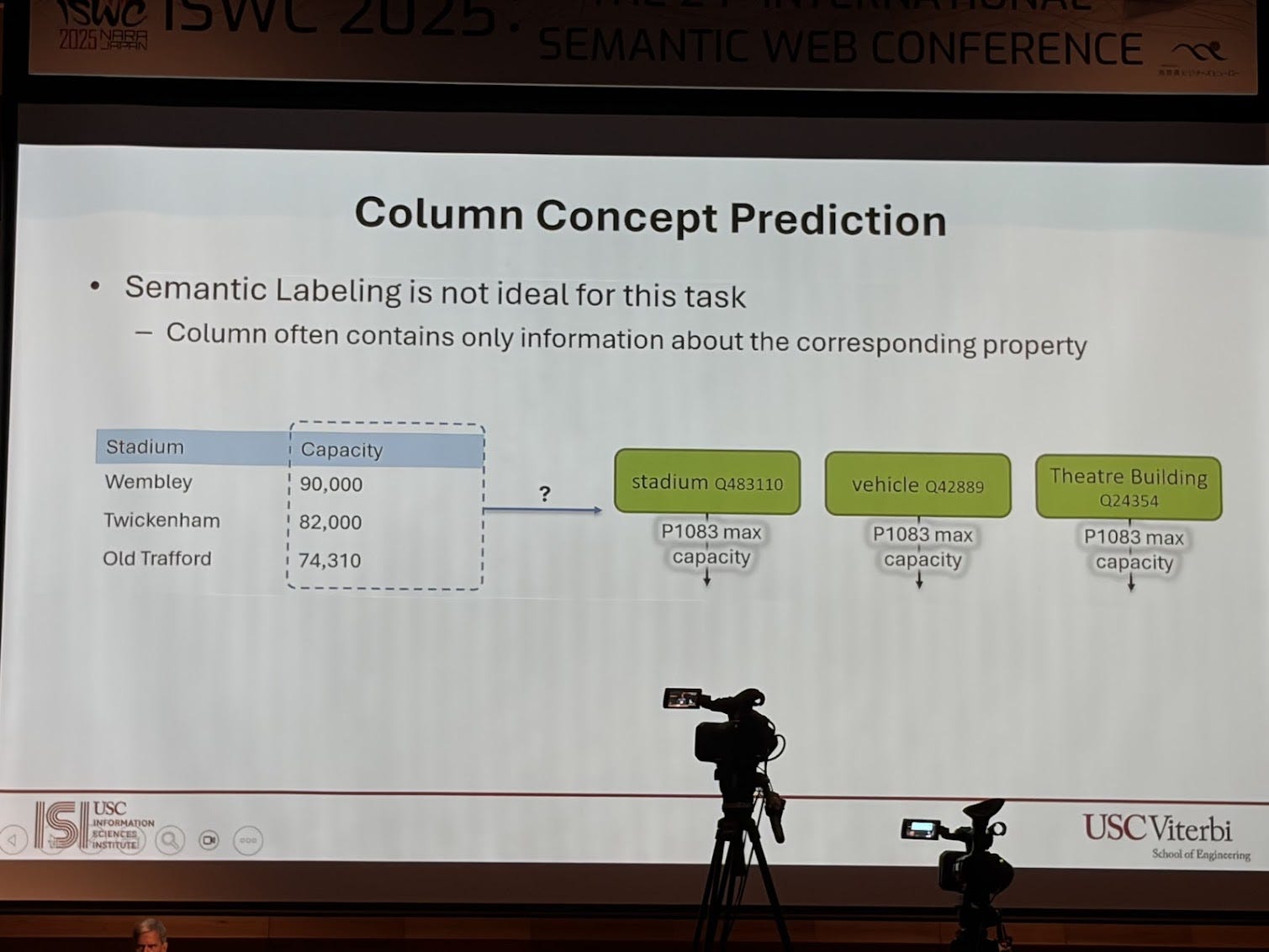
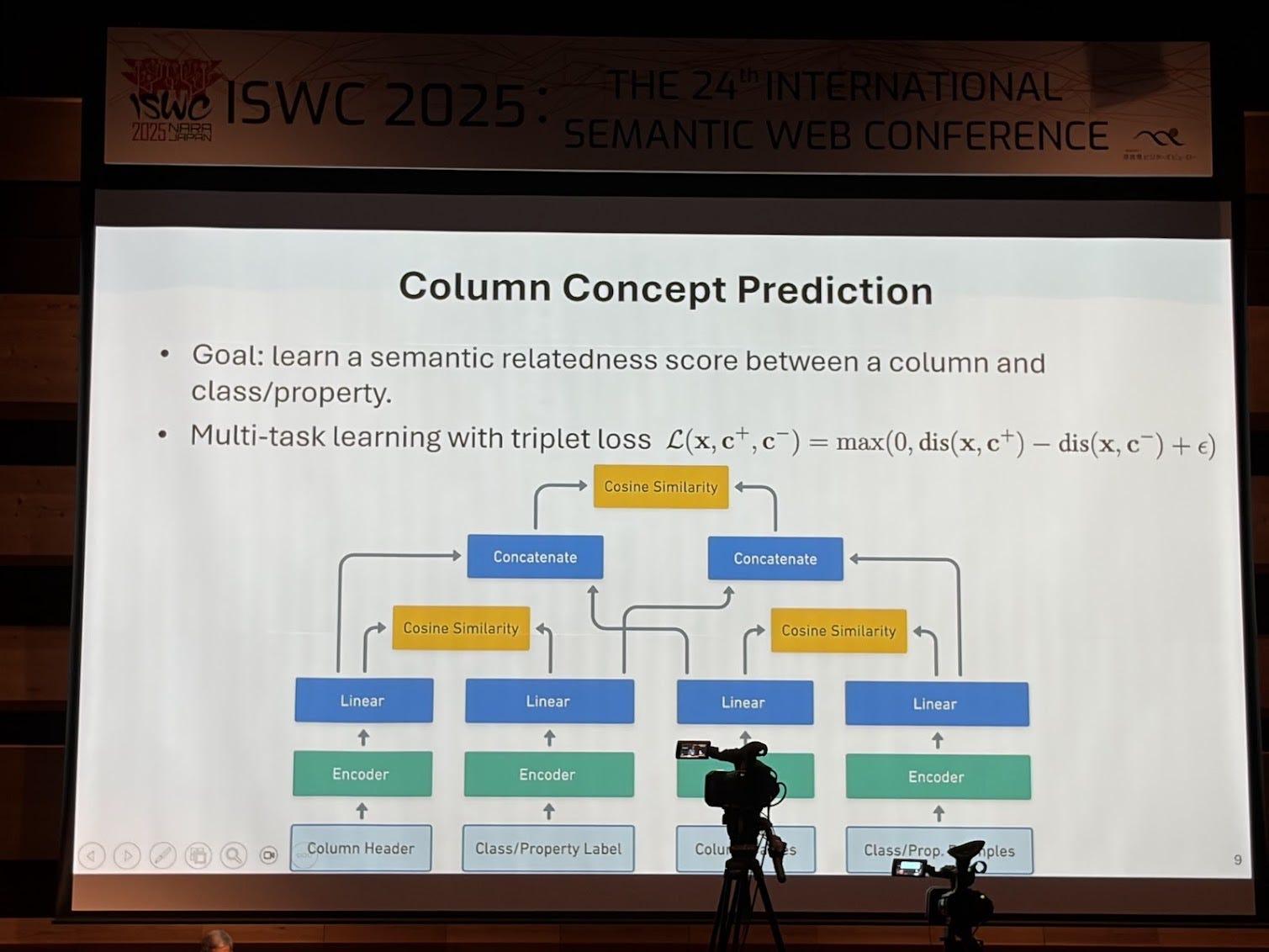
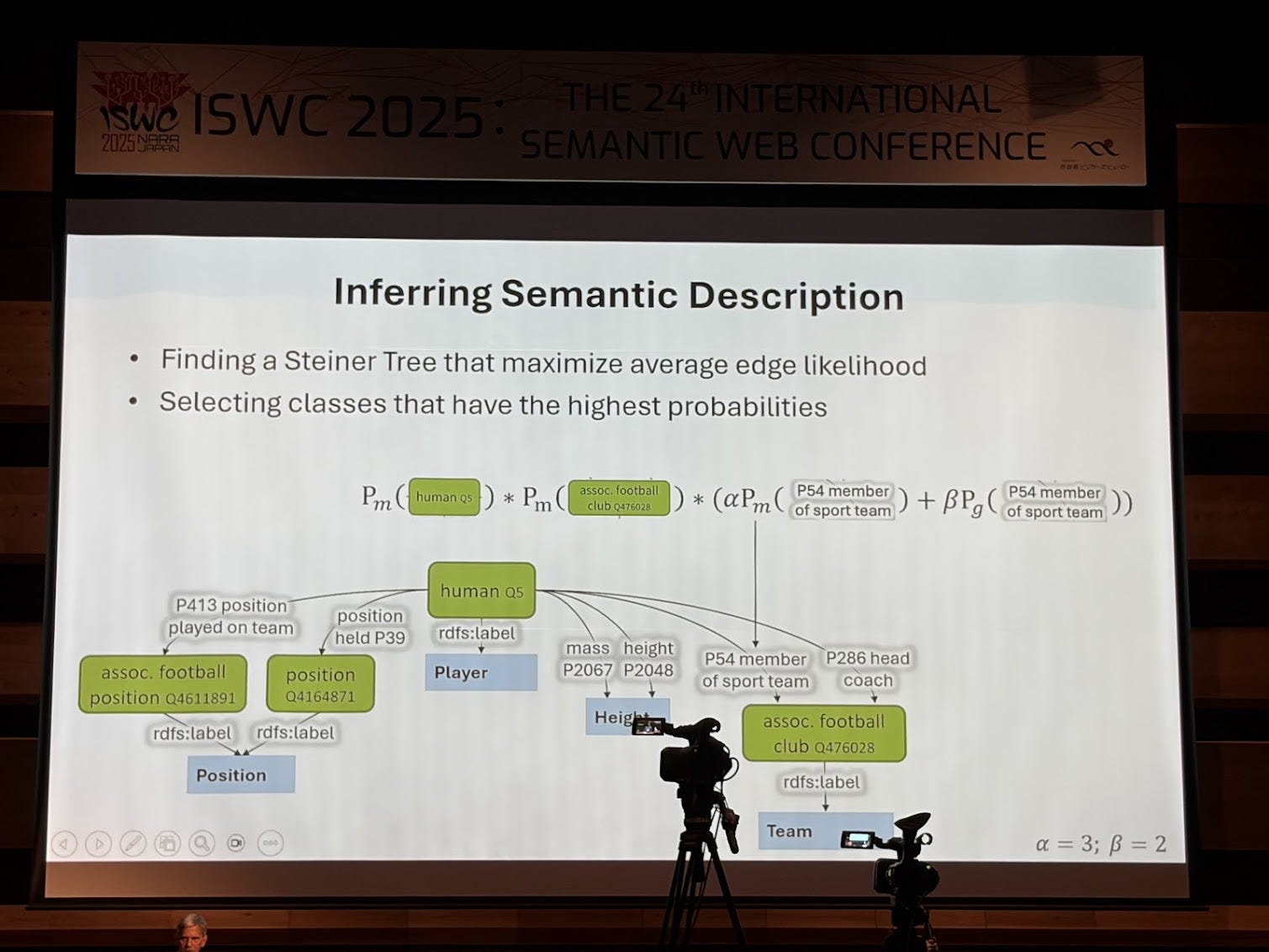

They are applying this work to creating knowledge graphs of critical minerals from reports. This work was nominated for best in-use paper award.

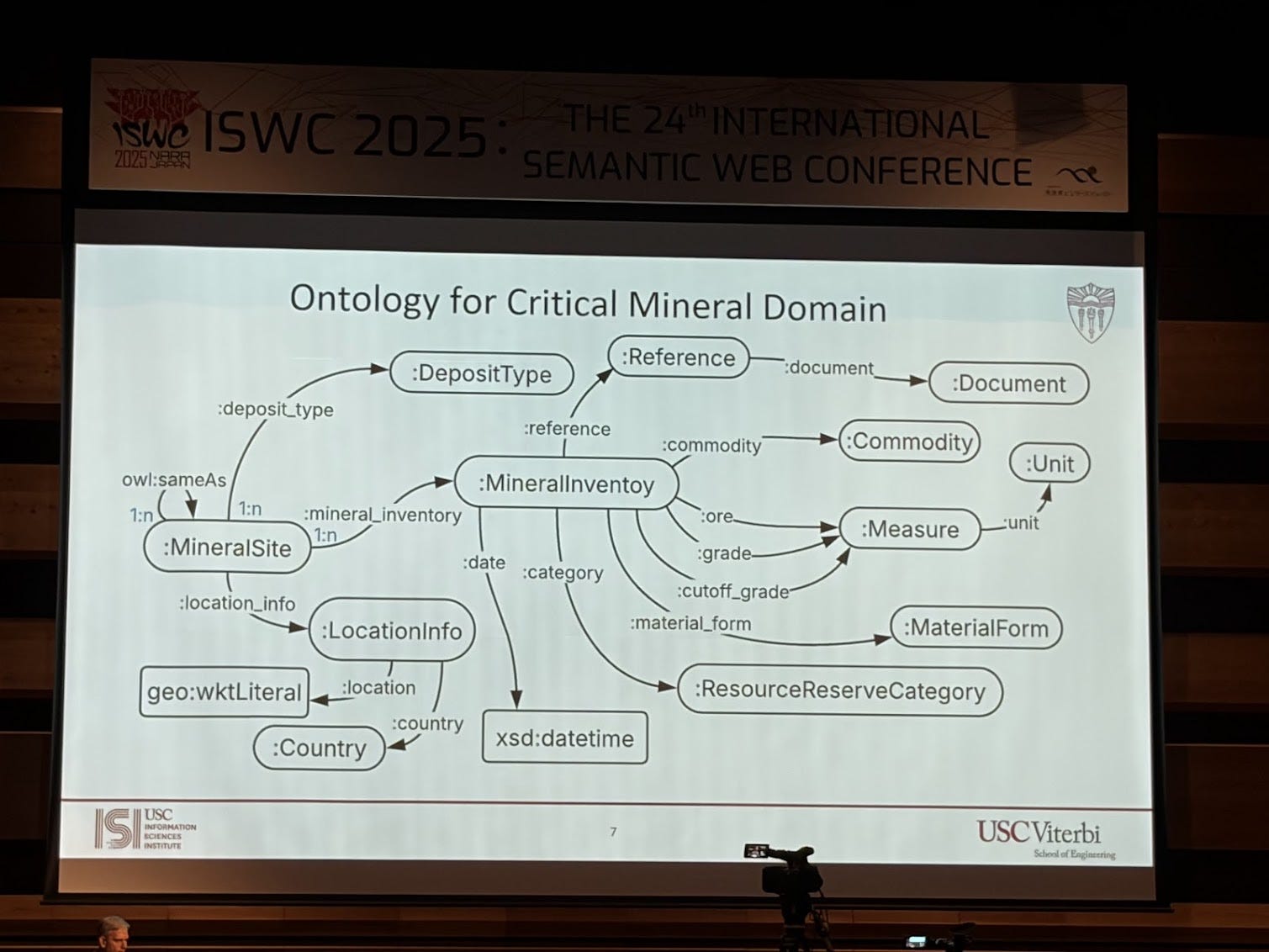


I’m feeling a shift from a generic “take text and generate a knowledge graph,” towards domain-specific inputs with specific use cases. That’s the difference. Creating knowledge graphs from text without a concrete use case… yeah, you can chase accuracy numbers, but then so what? It really depends on the use case, and use cases are always tied to domains. Nevertheless, the domain specific approaches build on the shoulders of giants who have been focused on the generic use cases.
Databases
One of the cool things about ISWC is the diversity of topics, which includes databases.
Another very interesting, and controversial paper, was about a benchmark “Sparqloscope: A generic benchmark for the comprehensive and concise performance evaluation of SPARQL engines”, presented by the developers of QLever database (github repo).
Two things stood out. First, the benchmark is actually quite interesting because traditionally benchmarks provide a particular dataset—one that can be scaled—and then a query workload over that dataset. But what they do in this benchmark is different: you provide the input dataset, and SparkleScope will automatically generate a set of SPARQL queries meant to evaluate very specific functions or features of a SPARQL engine.
So it auto-generates queries that essentially test every SPARQL feature. In a way, it’s like having a big suite of unit tests, but instead of correctness, these unit tests are designed to check performance. The presumed takeaway is that if a system performs well on all these micro-benchmarks (each focused on a particular SPARQL feature), then it will probably perform well overall on many real-world workloads. Anecdotally, that sounds believable, but they didn’t provide strong evidence. Just intuition.
Second, when you look at the benchmark results, QLever obviously comes out number one. This raises an eyebrow because the same team created the benchmark, ran the benchmark, and ranked their system best. There has been some controversy around this (Ruben started a discussion on LinkedIn calling this out and has a lot of fascinating comments, so get your popcorn out!). One of the points was that many of the benchmark queries were simple COUNT queries, which tend to perform very well and avoid returning full result sets. As always, the devil’s in the details.
But overall, I still think it’s an interesting benchmark. It’s not meant to replace dataset + query workload evaluation, but rather complement it. It adds a different type of stress test for SPARQL systems.
Finally, on QLever itself: anecdotally, I keep hearing great things about it. I think QLever could become the DuckDB for RDF graphs. I’ve heard a lot of positive buzz, so it’s worth taking a look if you haven’t yet. Note: I am not endorsing QLever, just sharing what I’m hearing.
My Chilean friends always do great research. They presented “Graph Querying or Similarity Search? Both!” Another paper I need to dig into the details. If you are building graph systems that need to combine querying and similarity, then this is for you.


More interesting topics
Are we evaluating LLM apps correctly? A criticism that Heiko Paulheim presented was that all evaluations using LLMs today should be taken with a grain of salt because LLMs have basically seen everything on the web.
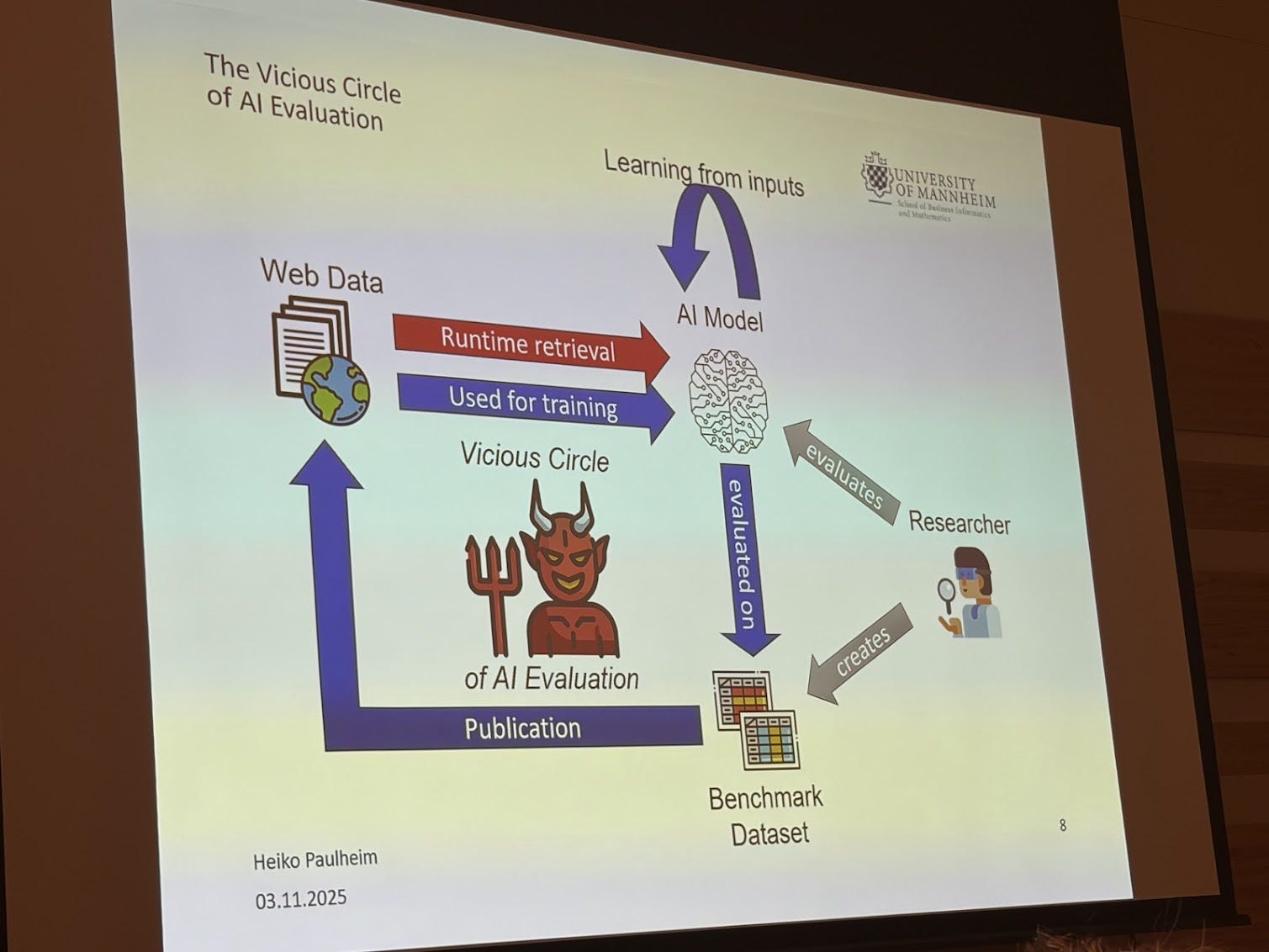
If we’re using LLMs to do all these tasks and then evaluating them with other LLMs, we really can’t guarantee the results mean anything, because the evaluation data has most likely already been seen during training.
Heiko’s point was that we must rethink how we generate evaluation data. His approach is that:
We need to trash all current evaluation datasets.
We need to generate new, truly unseen evaluation data.
We must evaluate on this new data and then trash it again.
The idea is that if we publish this new evaluation data on the web, the next generation of LLMs will train on it, and then it loses its value as a true test set. So evaluation sets must remain ephemeral and not publicly shared. This is a great point for thinking about evaluation in general: we need to take all LLM evaluations with a grain of salt.
Roberto Navigli gave a keynote at the RAG Knowledge Graph workshop exploring semantics in the age of LLMs.


This is a killer slide providing reasons why LLMs are not enough just by themselves:
Explicit semantics help validate LLMs
LLMs are not there yet when it comes to less resourced languages
Ground text to explicit entries


Btw, if I have ever brought up the notion of Ikigai to you, it’s because I learned that from Roberto.
Denny Vrandecic gave a keynote on Wikipedia and the Semantic Web, celebrating 20 years of co-development. It was a beautiful ride through history and a reminder that the most important innovation is the encyclopedia and semantics... it’s the Web!

Denny has been a pioneer because he is thinking ahead of everyone else. When everyone was focused on the encyclopedia and text, he observed the need to focus on data such that it can be defined once and reused everywhere. That led to Wikidata. For a few years, he has been working on the next thing. What is another thing that should be defined once and reused everywhere? Functions! Take a look at Wikifunctions, a very ambitious project to create and maintain a library of code functions.
Data quality is always an important topic and in the RDF knowledge graph, data quality rules/constraints can be represented as shapes over the graph, e.g. an order must have exactly one shipping address. The standard to do this is SHACL. What’s great is that the constraints are defined in terms of the ontology, in other words, in terms of the business. When violations occur, the logs can be difficult to analyze. There was an interesting paper “SHACL Dashboard: Analyzing Data Quality Reports over Large-Scale Knowledge Graphs” (github repo) that gave me inspiration on how we can define data quality dashboards for constraints and violations

Imagine “crawling” the knowledge inside an LLM and turning that into a knowledge graph? Check out gptkb.org This was such a cool demo! They won the best demo award and very much deserved it. The whole process cost ~$14K for OpenAI API calls and took 18 days.

Another cool poster: an ontology for the Football Common Data Format. Apparently an emerging standard to share football related data.

Awards
Congratulations to everyone receiving awards. These are papers that should be on your to-read list!
SWSA Ten-Year Award 2025: “RDFox: A Highly-Scalable RDF Store”. Note that RDFox spun out to Oxford Semantics Technology, which was acquired by Samsung.
Best Research Paper: FLORA: Unsupervised Knowledge Graph Alignment by Fuzzy Logic
Best Student Paper: Revisiting Link Prioritization for Efficient Traversal in Structured Decentralized Environments
Best Resource Paper: MammoTab 25: A Large-Scale Dataset for Semantic Table Interpretation -- Training, Testing, and Detecting Weaknesses
Best In-Use Paper: Open Government Data as Multi-dimensional 5 Star Data: cube.link
Best Poster: “Unveiling the Butterfly Effect in Knowledge Editing for Large Language Models Using Knowledge Graph-based Analysis”
Best Demo: “Introducing GPTKB to the Semantic Web
Demo Audience Choice Award: CHeCLOUD—the Cultural Heritage Linked Open Data Cloud
ISWC 2025 SemTab Challenge: “ADFr: Knowledge Graph Entity Linking via Interactive Reasoning and Exploration with GRASP”
ORKG Comparison Award: “CompoST: A Benchmark for Analyzing the Ability of LLMs To Compositionally Interpret Questions in a QALD Setting”
Final thoughts
As a fresh PhD student, I attended the 2008 Summer School on Ontology Engineering and Semantic Web (can’t believe that website is still online!) and met many other students who would end up becoming great friends and colleagues. Here are a few of us students, 17 years later: Maria Maleshkova, Professor at Helmut Schmidt University; Anna Lisa Gentile, Senior Research Scientist at IBM Research (and General Chair of ISWC2025!); Tara Raafat, Head of Metadata and Knowledge Graph at Bloomberg; together with the tutors Oscar Corcho, John Domingue and Natasha Noy. Attending this summer school was a pivotal moment for my career and I am extremely grateful for all the opportunities that have presented through the community I have been part of.

The conference organization was amazing! Congrats to the entire team and their leaders, General Chair Anna Lisa Gentile and Local Chair Kouji Kozaki.
Karaoke in Japan is so much fun. Last time we did this was at ISWC 2016 in Kobe.
The deers in Nara park is so weird and fun.
The Dagstuhl style workshops were a hit. They ran as half day sessions during the first two days of the conference. Then during the last three days, we gave each one a 1.5 hour slot so they could wrap discussions. Each of those sessions were packed. Really excited to learn what comes out of this.
Very happy to see industry folks attending. There were industry presentations from Bosch, Siemens, Hitachi, Samsung, Amazon, IBM, Rockwell, Huawei, valantic, among others. There were other key people from key organizations. Won’t name names, but these were the folks who were here definitely figuring out where the puck is heading.
Talking about industry, I will be one of the Sponsorship Chairs for next year. If you are looking to hire the best talent and learn about where things are going, please consider supporting the conference. I will be reaching out :)
And talking about next year… ISWC2026 will be in Bari, Italy Oct 25-29! You do not want to miss that!

Yeah, I’ve seen people warning against “introducing” knowledge engineering for AI - but that’s so… off. It was introduced in the 1970s